


A Sensible Information to Constructing Native RAG Functions with Langchain
Picture by Creator | Ideogram
Retrieval augmented technology (RAG) encompasses a household of techniques that reach typical language fashions, giant and in any other case (LLMs), to include context primarily based on retrieved information from a doc base, thereby resulting in extra truthful and related responses being generated upon person queries.
On this context, LangChain attained explicit consideration as a framework that simplifies the event of RAG purposes, offering orchestration instruments for integrating LLMs with exterior information sources, managing retrieval pipelines, and dealing with workflows of various complexity in a strong and scalable method.
This text supplies a observe step-by-step information to constructing a quite simple native RAG software with LangChain, defining at every step the important thing parts wanted. To navigate you thru this course of, we shall be utilizing Python. This text is meant to be an introductory sensible useful resource that dietary supplements the RAG foundations coated within the Understanding RAG series. If you’re new to RAG and in search of a delicate theoretical background, we advocate you take a look at this text sequence first!
Step-by-Step Sensible Information
Let’s get our palms soiled and discover ways to construct our first native RAG system with Langchain by coding. For reference, the next diagram taken from Understanding RAG Part II reveals a simplified model of a fundamental RAG system and its core parts, which we’ll construct by ourselves.
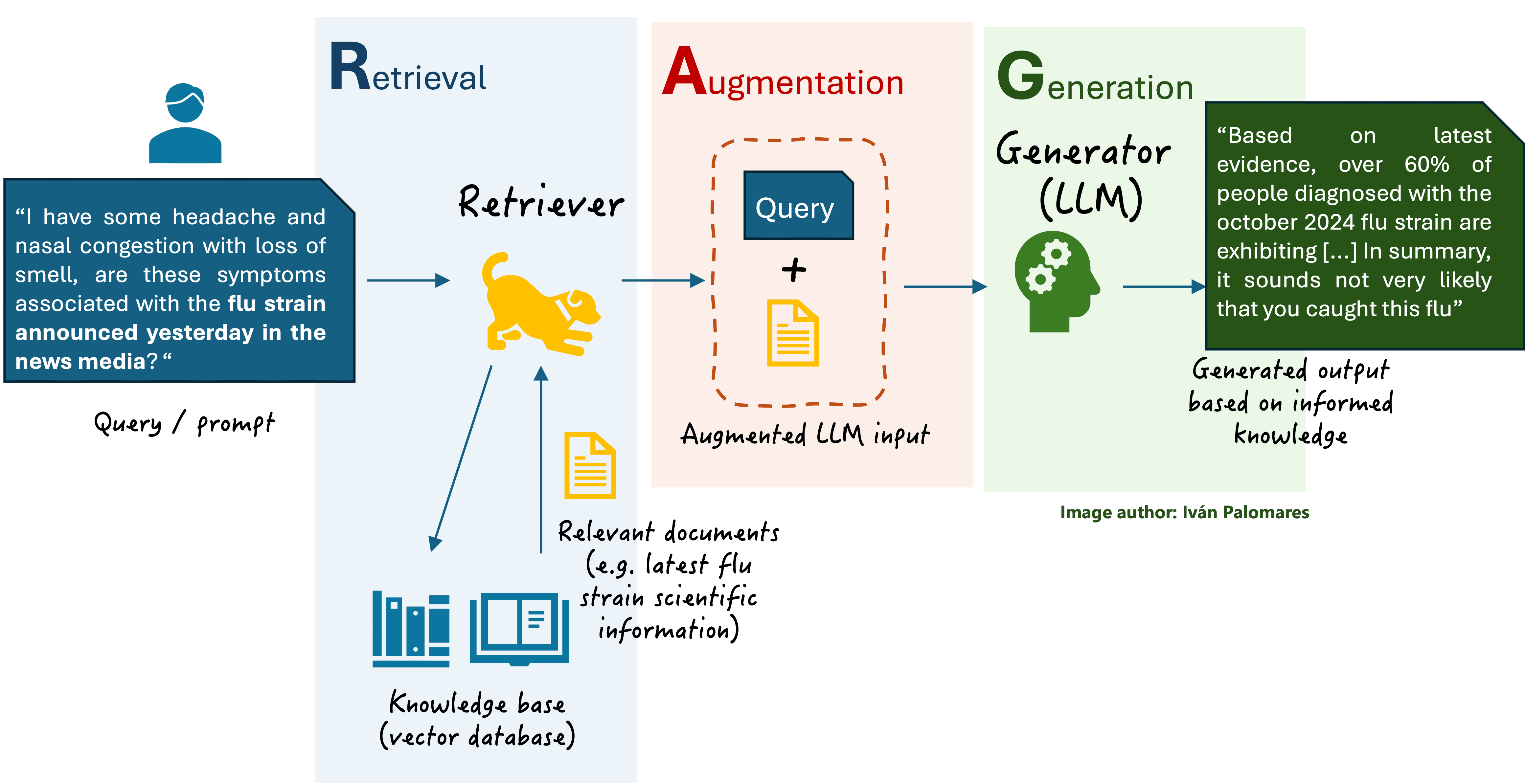
A fundamental RAG scheme
First, we set up the mandatory libraries and frameworks. The most recent variations of LangChain could require langchain-community, therefore it’s also being put in. FAISS is a framework for environment friendly similarity search in a vector database. For loading and utilizing current LLMs, we’ll resort to Hugging Face’s transformers and sentence-transformers libraries, the latter of which supplies pre-trained fashions optimized for textual content embeddings at sentence stage. Chances are you’ll or could not want the latter, relying on the particular Hugging Face mannequin you’ll use.
First we’ll set up the libraries outlined above.
|
pip set up langchain langchain_community faiss–cpu sentence–transformers transformers |
Subsequent, we add the mandatory imports to start out coding.
|
from langchain.llms import HuggingFacePipeline from langchain.chains import RetrievalQA from langchain.chains.question_answering import load_qa_chain from langchain.prompts import PromptTemplate from transformers import pipeline from langchain_community.vectorstores import FAISS |
The primary factor we’d like is a information base, carried out as a vector database. This shops the textual content paperwork that shall be utilized by the RAG system for context retrieval, and knowledge is often encoded as vector embeddings. We’ll use a small assortment of 9 quick textual content paperwork describing a number of locations in Japanese and Southeast Asia. The dataset is offered in a compressed .zip file here. The code beneath regionally downloads the dataset, decompresses it and extracts the textual content recordsdata.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import os import urllib.request import zipfile
zip_url = “https://github.com/gakudo-ai/open-datasets/uncooked/refs/heads/most important/asia_documents.zip” zip_path = “asia_documents.zip” extract_folder = “asia_txt_files”
print(“Downloading zip file…”) urllib.request.urlretrieve(zip_url, zip_path) print(“Obtain full!”)
print(“Extracting recordsdata…”) os.makedirs(extract_folder, exist_ok=True) with zipfile.ZipFile(zip_path, “r”) as zip_ref: zip_ref.extractall(extract_folder)
print(f“Information extracted to: {extract_folder}”)
print(“Extracted recordsdata:”) print(os.listdir(extract_folder)) |
Now that we now have a “uncooked” information base of textual content paperwork, we have to cut up the entire information into chunks and remodel them into vector embeddings.
Chunking in RAG techniques is vital as a result of LLMs have token limitations, and environment friendly retrieval of related info requires splitting paperwork into manageable items whereas holding contextual integrity, which is essential for sufficient response technology by the LLM afterward.
Concerning paperwork transformation into chunks into an appropriate vector database for our RAG software, FAISS will take care of effectively storing and indexing the vector embeddings, enabling correct and environment friendly similarity-based search. The as_retriever() technique facilitates integration with LangChain’s retrieval strategies, in order that related doc chunks may be retrieved dynamically to optimize the LLM’s responses. Discover that for creating embeddings we’re utilizing a Hugging Face mannequin skilled for this job, concretely all-MiniLM-L6-v2.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import os from langchain_community.document_loaders import TextLoader from langchain.text_splitter import CharacterTextSplitter from langchain_community.embeddings import HuggingFaceEmbeddings
folder_path = “asia_txt_files”
paperwork = [] for filename in os.listdir(folder_path): if filename.endswith(“.txt”): file_path = os.path.be a part of(folder_path, filename) loader = TextLoader(file_path) paperwork.prolong(loader.load())
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=100) docs = text_splitter.split_documents(paperwork)
embedding_model = HuggingFaceEmbeddings(model_name=“sentence-transformers/all-MiniLM-L6-v2”)
vectorstore = FAISS.from_documents(docs, embedding_model) retriever = vectorstore.as_retriever() |
We simply initialized one among our key RAG parts on the finish of the earlier code excerpt: the retriever. To make it totally useful, after all, we have to begin gluing the remainder of the RAG items collectively.
Under, we totally unleash LangChain’s orchestration capabilities. The next code first defines an LLM pipeline for textual content technology utilizing Hugging Face’s Transformers library and the GPT-2 mannequin.
The machine=0 argument ensures the mannequin runs on a GPU (if accessible), considerably enhancing inference pace. If you’re operating this code on a pocket book, we propose holding it as is. The max_new_tokens argument is vital to manage the size of the generated response, stopping excessively lengthy or truncated outputs whereas sustaining coherence. Strive enjoying with its worth later to see the way it impacts the standard of the generated outputs.
|
from langchain.chains import LLMChain from langchain.prompts import PromptTemplate from langchain.chains import RetrievalQA from transformers import pipeline
llm_pipeline = pipeline(“text-generation”, mannequin=“gpt2”, machine=0, max_new_tokens=200) llm = HuggingFacePipeline(pipeline=llm_pipeline) |
Issues get more and more thrilling beneath. Subsequent, we outline a immediate template, i.e. a structured and formatted immediate that includes the retrieved context dynamically, making certain the mannequin generates responses grounded in related information. This step aligns with the Augmentation block within the beforehand mentioned RAG structure.
We then outline an LLM chain, a key LangChain part that orchestrates the interplay between the LLM and the immediate template that may comprise the augmented enter and guarantee a structured query-response circulate.
Final however not least, we initialize an object for Query-Answering (QA) utilizing the RetrievalQA class. In LangChain, specifying the kind of goal language job after having created the chain is essential to outline an software suited to that individual job, as an illustration, question-answering. The aforesaid class hyperlinks the retriever with the LLM chain. Now, we now have all of the RAG constructing blocks glued collectively!
|
prompt_template = “Reply the next query primarily based on the supplied context: {context}nnQuestion: {question}nAnswer:”
immediate = PromptTemplate(input_variables=[“query”, “context”], template=prompt_template)
llm_chain = LLMChain(llm=llm, immediate=immediate)
retrieval_qa = RetrievalQA.from_chain_type( llm=llm, chain_type=“stuff”, retriever=retriever, verbose=True ) |
We’re almost achieved and nearly able to strive our RAG software. Only one extra step to outline a supporting perform that may make sure the augmented context is stored inside the LLM’s specified token restrict, truncating the enter when wanted.
|
def truncate_to_max_tokens(textual content, max_tokens=500): tokens = textual content.cut up() if len(tokens) > max_tokens: return ” “.be a part of(tokens[:max_tokens]) return textual content |
Time to strive our RAG system with a query about Asian delicacies. Let’s see the way it behaves (notice, maintain expectations not too excessive, bear in mind we’re coping with smaller and manageable pre-trained fashions for studying functions. Don’t count on a ChatGPT-like output high quality right here!). You possibly can strive later altering the variety of high Okay retrieved paperwork to make use of in augmentation, by changing the worth of 1 within the commented line beneath by a worth of two or extra.
|
question = “What are one of the best Asian delicacies dishes?”
# IMPORTANT: utilizing solely the top-1 doc by default retrieved_docs = retriever.get_relevant_documents(question)[:1] context = ” “.be a part of([doc.page_content for doc in retrieved_docs]) context = truncate_to_max_tokens(context, max_tokens=500) response = retrieval_qa.run(question) print(“Reply:”, response) |
It is a pattern response:
Query: What are one of the best Asian delicacies dishes?
Useful Reply: Many individuals have an urge to drink their “bitter” (bitter meals) as a way to get good outcomes. This consists of many well-liked Asian dishes, together with spicy-spicy rice, pinto beans, soy sauce, and extra. Many Asian meals firms have been utilizing candy (a mix of soy sauce, bitter cream, and a mix of watermelon, cabbage, and ginger) as the first parts, which has led to many individuals having fun with conventional Chinese language, Japanese, and Vietnamese meals that may be scrumptious.
Vietnamese meals tends to be extra interesting and extra interesting to Vietnamese college students and professionals who need to study in regards to the nation, and will need to take the time to review and/or take programs for an A+ or above.
Japanese delicacies is a combined bag. The most well-liked dishes in Japanese delicacies are typically fried rice (鼘雅), fried greens (鞊雅) and seaweed (雅枊), however different…
Not too unhealthy. There could have been a little bit of inconsistent blends of data in some elements of the textual content, however total we are able to see how the system made an honest use of retrieved info from our authentic dataset of textual content paperwork, along with the standard, restricted capabilities of GPT-2, largely influenced by the general-purpose dataset it has been skilled upon.
Wrapping Up
We now have taken a delicate hands-on introductory have a look at constructing your first RAG software regionally, counting on LangChain for orchestrating its most important parts, primarily the retriever and the language mannequin. Utilizing these steps and methods to construct your personal native RAG software suited to your specs, the sky’s the restrict.
Source link