

A context vector is a numerical illustration of a phrase that captures its that means inside a selected context. Not like conventional phrase embeddings that assign a single, fastened vector to every phrase, a context vector for a similar phrase can change relying on the encircling phrases in a sentence. Transformers are the software of alternative for producing context vectors at this time. On this tutorial, you’ll discover how one can generate and work with context vectors utilizing transformer fashions. Particularly, you’ll be taught:
- How context vectors seize contextual data
- The right way to extract context vectors utilizing a transformer mannequin
- The right way to use context vectors for contextual phrase disambiguation
- The right way to visualize consideration patterns in a transformer mannequin
Let’s get began!

Producing and Visualizing Context Vectors in Transformers
Photograph by Anna Tarazevich. Some rights reserved.
Overview
This put up is split into three elements; they’re:
- Understanding Context Vectors
- Visualizing Context Vectors from Completely different Layers
- Visualizing Consideration Patterns
Understanding Context Vectors
Not like conventional phrase embeddings (corresponding to Word2Vec or GloVe), which assign a hard and fast vector to every phrase no matter context, transformer fashions generate dynamic representations that depend upon surrounding phrases.
For instance, within the sentences “I’m going to the financial institution to deposit cash” and “I’m going to take a seat by the river financial institution,” the phrase “financial institution” has completely different meanings. A conventional phrase embedding would assign the identical vector to “financial institution” in each sentences, however a transformer mannequin generates completely different context vectors that seize the distinct meanings primarily based on the encircling phrases.
The ability of context vectors is that they seize the that means of phrases of their particular contexts, permitting you to work with the **that means** reasonably than the person phrases in a sentence. Context vectors are not like phrase embeddings, that are retrieved from a lookup desk; as a substitute, you want a complicated mannequin to generate them. Transformer fashions are sometimes used as a result of they will produce high-quality context vectors.
Let’s see an instance of how one can generate context vectors from a transformer mannequin:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
import numpy as np import torch from transformers import BertModel, BertTokenizer
# Load pre-trained mannequin and tokenizer tokenizer = BertTokenizer.from_pretrained(“bert-base-uncased”) mannequin = BertModel.from_pretrained(“bert-base-uncased”) mannequin.eval() # for security: set to analysis mode
def get_context_vectors(sentence, mannequin, tokenizer): inputs = tokenizer(sentence, return_tensors=“pt”, add_special_tokens=True) input_ids = inputs[“input_ids”] attention_mask = inputs[“attention_mask”]
# Get the tokens (for reference) tokens = tokenizer.convert_ids_to_tokens(input_ids[0])
# Ahead cross, get all hidden states from every layer with torch.no_grad(): outputs = mannequin(input_ids, attention_mask=attention_mask, output_hidden_states=True) hidden_states = outputs.hidden_states
# Every component in hidden states has form (batch_size, sequence_length, hidden_size) # Right here takes the primary component within the batch from the final layer last_layer_vectors = hidden_states[–1][0].numpy() # Form: (sequence_length, hidden_size)
return tokens, last_layer_vectors
# Get context vectors from instance sentences with ambiguous phrases sentence1 = “I’ll the financial institution to deposit cash.” sentence2 = “I’ll sit by the river financial institution.” tokens1, vectors1 = get_context_vectors(sentence1, mannequin, tokenizer) tokens2, vectors2 = get_context_vectors(sentence2, mannequin, tokenizer)
# Print the tokens for reference print(“Tokens in sentence 1:”, tokens1) print(“Tokens in sentence 2:”, tokens2)
# Discover the index of “financial institution” in each sentences bank_idx1 = tokens1.index(“financial institution”) bank_idx2 = tokens2.index(“financial institution”)
# Get the context vectors for “financial institution” in each sentences bank_vector1 = vectors1[bank_idx1] bank_vector2 = vectors2[bank_idx2]
# Calculate cosine similarity between the 2 “financial institution” vectors # decrease similarity means that means is completely different def cosine_similarity(vec1, vec2): return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
similarity = cosine_similarity(bank_vector1, bank_vector2) print(f“Cosine similarity between ‘financial institution’ vectors: {similarity:.4f}”) |
This code masses a pre-trained BERT mannequin and tokenizer. A perform get_context_vectors() is outlined to extract context vectors from a sentence. The perform takes a sentence, passes it via the mannequin, and collects the “hidden states” from every layer by setting output_hidden_states=True. These hidden states come from every layer of the transformer mannequin, and all share the identical form because of the mannequin’s constant construction.
Sometimes, a transformer mannequin features a task-specific head (e.g., for predicting the subsequent phrase in a sentence). Right here, you’re not utilizing the pinnacle; as a substitute, you’re analyzing what will get handed to the pinnacle as enter. If the pinnacle could make significant predictions, the enter should already comprise helpful details about the sentence.
Observe that the mannequin enter is a sequence of tokens, and every layer within the transformer maintains the identical sequence size. Thus, as soon as you discover the place of the phrase “financial institution” in every sentence, you may extract the corresponding vector from the final hidden state and compute the cosine similarity between the 2 vectors.
Cosine similarity is a measure starting from -1 to 1. A decrease similarity means the meanings are extra completely different. Once you run the code, you’ll see:
|
Tokens in sentence 1: [‘[CLS]’, ‘i’, “‘”, ‘m’, ‘going’, ‘to’, ‘the’, ‘financial institution’, ‘to’, ‘deposit’, ‘cash’, ‘.’, ‘[SEP]’] Tokens in sentence 2: [‘[CLS]’, ‘i’, “‘”, ‘m’, ‘going’, ‘to’, ‘sit’, ‘by’, ‘the’, ‘river’, ‘financial institution’, ‘.’, ‘[SEP]’] Cosine similarity between ‘financial institution’ vectors: 0.5327 |
This reveals the identical phrase “financial institution” is certainly fairly completely different within the two sentences.
Visualizing Context Vectors from Completely different Layers
Transformer fashions like BERT have a number of layers, and every layer captures completely different facets of the textual content. Just like the case of laptop imaginative and prescient utilizing convolutional neural networks, the early layers seize low-level options (e.g., edges, corners), and the later layers seize higher-level options (e.g., shapes, objects). Within the case of transformer fashions, the early layers seize syntactic data (e.g., whether or not a noun is singular or plural), and the later layers seize semantic data (what the phrase means within the sentence).
Because the illustration modifications throughout layers, let’s discover how one can extract and analyze context vectors from completely different layers:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
import matplotlib.pyplot as plt import numpy as np import torch from transformers import BertModel, BertTokenizer
# Load pre-trained mannequin and tokenizer tokenizer = BertTokenizer.from_pretrained(“bert-base-uncased”) mannequin = BertModel.from_pretrained(“bert-base-uncased”) mannequin.eval() # for security: set to analysis mode
def get_all_layer_vectors(sentence, mannequin, tokenizer): inputs = tokenizer(sentence, return_tensors=“pt”, add_special_tokens=True) input_ids = inputs[“input_ids”] attention_mask = inputs[“attention_mask”]
# Get the tokens (for reference) tokens = tokenizer.convert_ids_to_tokens(input_ids[0])
# Ahead cross, get all hidden states from every layer with torch.no_grad(): outputs = mannequin(input_ids, attention_mask=attention_mask, output_hidden_states=True) hidden_states = outputs.hidden_states
# Convert from torch tensor to numpy arrays, take solely the primary component within the batch all_layers_vectors = [layer[0].numpy() for layer in hidden_states]
return tokens, all_layers_vectors
# Get vectors from all layers for a sentence sentence = “The short brown fox jumps over the lazy canine.” tokens, all_layers = get_all_layer_vectors(sentence, mannequin, tokenizer) print(f“Variety of layers (together with embedding layer): {len(all_layers)}”)
# Let’s analyze how the illustration of a phrase modifications throughout layers phrase = “fox” word_idx = tokens.index(phrase)
# Extract the vector for this phrase from every layer word_vectors_across_layers = [layer[word_idx] for layer in all_layers]
# Calculate the cosine similarity between consecutive layers def cosine_similarity(vec1, vec2): return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
similarities = [] for i in vary(len(word_vectors_across_layers) – 1): sim = cosine_similarity(word_vectors_across_layers[i], word_vectors_across_layers[i+1]) similarities.append(sim)
# Plot the similarities plt.determine(figsize=(10, 6)) plt.plot(similarities, marker=‘o’) plt.title(f“Cosine Similarity Between Consecutive Layers for ‘{phrase}'”) plt.xlabel(‘Layer Transition’) plt.ylabel(‘Cosine Similarity’) plt.xticks(vary(len(similarities)), [f“{i}->{i+1}” for i in range(len(similarities))]) plt.grid(True) plt.present() |
This code makes use of the identical mannequin because the earlier instance, with an analogous circulate. The perform get_all_layer_vectors() returns hidden states from all layers in NumPy array format, reasonably than simply the final layer.
Every hidden state is a tensor of form (batch dimension, sequence size, hidden dimension). The token sequence is remodeled by every layer, however the sequence size stays the identical. So, when you’ve situated the goal phrase within the sentence, you may extract its corresponding vector from every layer.
The code calculates the cosine similarity of a particular phrase’s vector throughout consecutive layers. Once you run it, you’ll see:
|
Variety of layers (together with embedding layer): 13 |
and the ensuing plot of cosine similarity between layers:
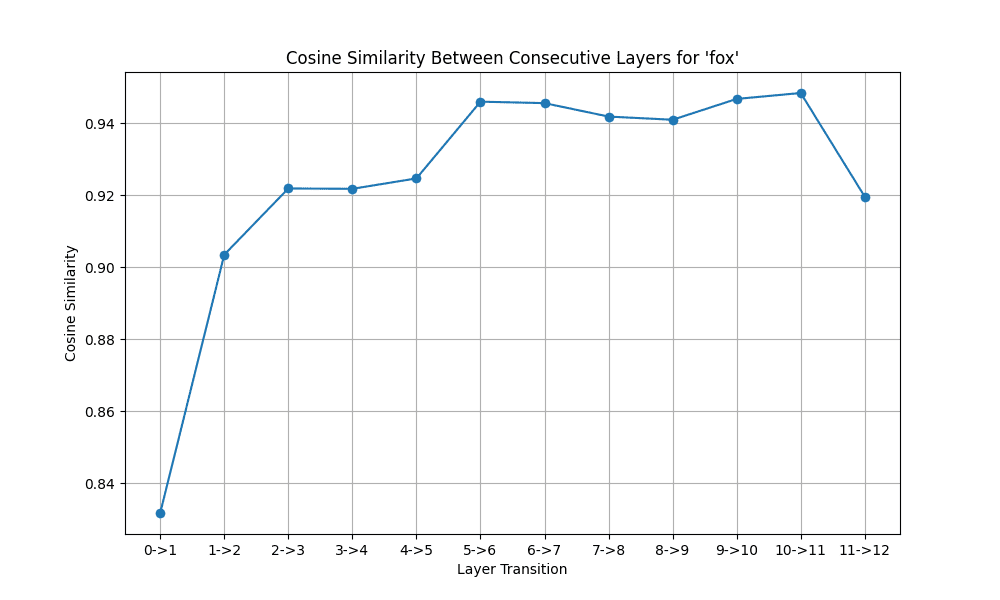
Plot exhibiting how the context vector modifications between layers in a mannequin
You’ll discover that the phrase’s illustration modifications considerably in early layers however stabilizes later. This helps the concept earlier layers deal with syntactic options, whereas later ones refine semantic that means.
Contextual Phrase Disambiguation
One of the crucial highly effective functions of context vectors is phrase sense disambiguation: figuring out which that means of a phrase is being utilized in a given context. This helps establish what number of distinct senses a phrase can have. Let’s implement a easy phrase sense disambiguation system utilizing context vectors:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
import numpy as np import torch from transformers import BertModel, BertTokenizer
# Load pre-trained mannequin and tokenizer tokenizer = BertTokenizer.from_pretrained(“bert-base-uncased”) mannequin = BertModel.from_pretrained(“bert-base-uncased”) mannequin.eval() # for security: set to analysis mode
def get_context_vectors(sentence, mannequin, tokenizer): inputs = tokenizer(sentence, return_tensors=“pt”, add_special_tokens=True) input_ids = inputs[“input_ids”] attention_mask = inputs[“attention_mask”]
# Get the tokens (for reference) tokens = tokenizer.convert_ids_to_tokens(input_ids[0])
# Ahead cross, get all hidden states from every layer with torch.no_grad(): outputs = mannequin(input_ids, attention_mask=attention_mask, output_hidden_states=True) hidden_states = outputs.hidden_states
# Every component in hidden states has form (batch_size, sequence_length, hidden_size) # Right here takes the primary component within the batch from the final layer last_layer_vectors = hidden_states[–1][0].numpy() # Form: (sequence_length, hidden_size)
return tokens, last_layer_vectors
def cosine_similarity(vec1, vec2): return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
def disambiguate_word(phrase, sentences, mannequin, tokenizer): “”“for phrase sense disambiguation”“”
# Get context vector of a phrase for every sentence word_vectors = [] for sentence in sentences: tokens, vectors = get_context_vectors(sentence, mannequin, tokenizer) for token_index, token in enumerate(tokens): if token == phrase: word_vectors.append({ ‘sentence’: sentence, ‘vector’: vectors[token_index] })
# Calculate pairwise similarities between all vectors n = len(word_vectors) similarity = np.zeros((n, n)) for i in vary(n): for j in vary(i, n): worth = cosine_similarity(word_vectors[i][‘vector’], word_vectors[j][‘vector’]) similarity[i, j] = similarity[j, i] = worth
# Run easy clustering to group vectors of excessive similarity threshold = 0.60 # Similarity > threshold would be the identical cluster clusters = []
for i in vary(n): # Examine if this vector belongs to any current cluster assigned = False for cluster in clusters: # Calculate common similarity with all vectors within the cluster avg_sim = np.imply([similarity[i, j] for j in cluster]) if avg_sim > threshold: cluster.append(i) assigned = True break # If not assigned to any cluster, create a brand new one if not assigned: clusters.append([i])
# Print the outcomes print(f“Discovered {len(clusters)} completely different senses for ‘{phrase}’:n”) for i, cluster in enumerate(clusters): print(f“Sense {i+1}:”) for idx in cluster: print(f” – {word_vectors[idx][‘sentence’]}”) print()
# Instance: Disambiguate the phrase “financial institution” sentences = [ “I’m going to the bank to deposit money.”, “The bank approved my loan application.”, “I’m going to sit by the river bank.”, “The bank of the river was muddy after the rain.”, “The central bank raised interest rates yesterday.”, “They had to bank the fire to keep it burning through the night.” ] disambiguate_word(“financial institution”, sentences, mannequin, tokenizer) |
On this instance, you outline a perform disambiguate_word() that takes a goal phrase and an inventory of sentences containing that phrase. The perform converts every sentence into context vectors utilizing get_context_vectors() and extracts the vector equivalent to the goal phrase.
With all of the context vectors of the identical phrase gathered, you compute cosine similarities between each pair and carry out clustering to group related ones. The clustering algorithm used right here is primary and threshold-based. You possibly can enhance it by utilizing extra subtle strategies like Okay-means or hierarchical clustering—accessible within the scikit-learn library—or incorporating extra options.
The results of the clustering is printed. If you happen to run the code, you will note:
|
Discovered 3 completely different senses for ‘financial institution’:
Sense 1: – I’ll the financial institution to deposit cash. – The financial institution authorised my mortgage utility. – The central financial institution raised rates of interest yesterday.
Sense 2: – I’ll sit by the river financial institution. – The financial institution of the river was muddy after the rain.
Sense 3: – They needed to financial institution the fireplace to maintain it burning via the evening. |
Whereas the output doesn’t explicitly label the meanings, you may observe that completely different senses of the phrase “financial institution” are recognized: as a monetary establishment, the facet of a river, or a verb that means to help or save from destruction. This demonstrates how context vectors can be utilized for phrase sense disambiguation.
This reveals that the phrase “financial institution” certainly has completely different representations in these sentences.
Visualizing Consideration Patterns
One other strategy to perceive how transformer fashions course of textual content is by visualizing their consideration patterns. The eye mechanism permits transformers to weigh the significance of various phrases when producing context vectors. In different phrases, consideration weights present how a lot every phrase “attends to” different phrases within the sentence.
Let’s implement a software to visualise consideration:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
import matplotlib.pyplot as plt import numpy as np import seaborn as sns import torch from transformers import BertTokenizer, BertModel
# Load pre-trained mannequin and tokenizer tokenizer = BertTokenizer.from_pretrained(“bert-base-uncased”) mannequin = BertModel.from_pretrained(“bert-base-uncased”) mannequin.eval() # for security: set to analysis mode
def get_attention_weights(sentence, mannequin, tokenizer): inputs = tokenizer(sentence, return_tensors=“pt”, add_special_tokens=True) input_ids = inputs[“input_ids”] attention_mask = inputs[“attention_mask”]
# Get the tokens (for reference) tokens = tokenizer.convert_ids_to_tokens(input_ids[0])
# Ahead cross, get consideration weights with torch.no_grad(): outputs = mannequin(input_ids, attention_mask=attention_mask, output_attentions=True)
# One weight for every consideration layer within the mannequin # Every component in has form (batch_size, num_heads, sequence_length, sequence_length) attentions = outputs.attentions
return tokens, attentions
def visualize_attention(tokens, attention_weights, layer, head): “”“visualize consideration for a selected layer and head”“”
# Get consideration weights for the desired layer and head # Form: (sequence_length, sequence_length) attn = attention_weights[layer][0, head].numpy()
# Create a determine and axis fig, ax = plt.subplots(figsize=(10, 8))
# Create a heatmap sns.heatmap(attn, xticklabels=tokens, yticklabels=tokens, cmap=“viridis”, ax=ax) ax.set_title(f“Consideration Weights – Layer {layer+1}, Head {head+1}”) ax.set_xlabel(“Token (Key)”) ax.set_ylabel(“Token (Question)”) plt.xticks(rotation=90) # Rotate x-axis labels for higher readability plt.tight_layout() plt.present()
def visualize_layer_attention(tokens, attention_weights, layer): “”“visualize the common consideration throughout all heads for a layer”“”
# Get common consideration weights throughout all heads for the desired layer # Form: (sequence_length, sequence_length) attn = attention_weights[layer][0].imply(dim=0).numpy()
# Create a determine and axis fig, ax = plt.subplots(figsize=(10, 8))
# Create a heatmap sns.heatmap(attn, xticklabels=tokens, yticklabels=tokens, cmap=“viridis”, ax=ax) ax.set_title(f“Common Consideration Weights – Layer {layer+1}”) ax.set_xlabel(“Token (Key)”) ax.set_ylabel(“Token (Question)”) plt.xticks(rotation=90) # Rotate x-axis labels for higher readability plt.tight_layout() plt.present()
# Get consideration weight from an instance sentence sentence = “The president of the US visited the capital metropolis.” tokens, attention_weights = get_attention_weights(sentence, mannequin, tokenizer)
# Visualize consideration for a selected layer and head # BERT base has 12 layers (0-11) and 12 heads per layer (0-11) layer_to_visualize = 5 # sixth layer (0-indexed) head_to_visualize = 7 # eighth consideration head (0-indexed) visualize_attention(tokens, attention_weights, layer_to_visualize, head_to_visualize)
# Visualize common consideration for a layer visualize_layer_attention(tokens, attention_weights, layer_to_visualize) |
Once you run this code, two heatmaps can be generated:
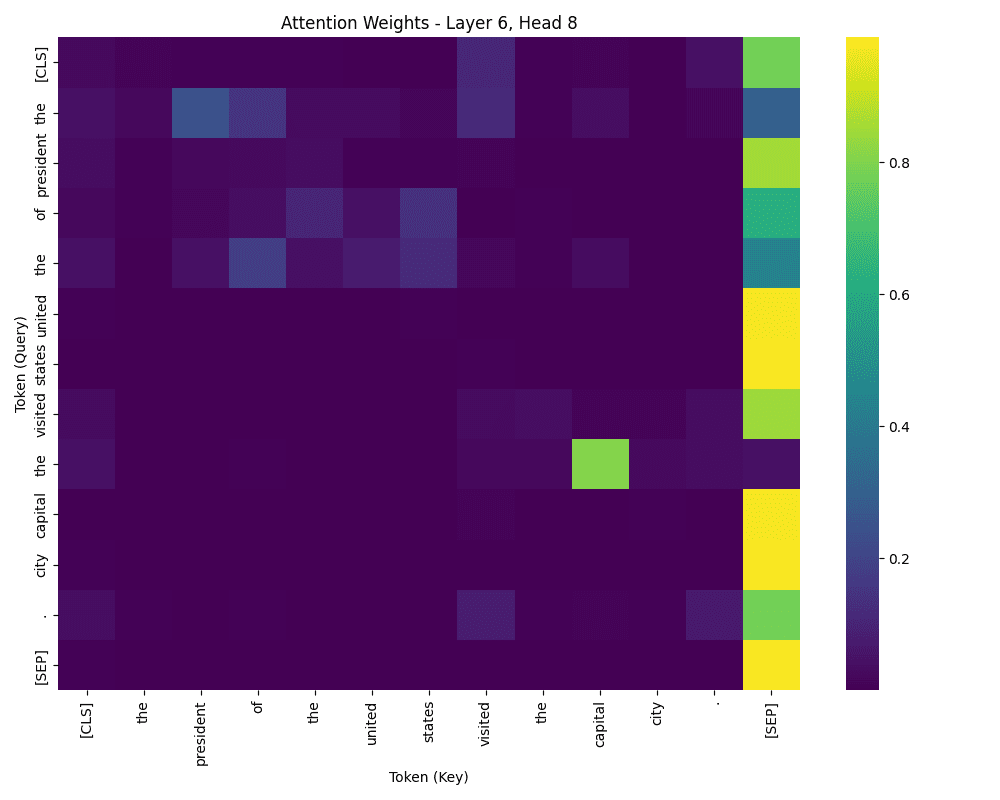
Consideration weights from one head

Common consideration weights from one layer
The primary heatmap reveals the eye weights for a selected layer and head. The x-axis represents the “key” tokens, and the y-axis represents the “question” tokens. Brighter colours point out stronger consideration.
The second heatmap reveals the common consideration weights throughout all heads in a layer.
The eye information is obtained by setting output_attentions=True when invoking the mannequin. Every head produces a sq. matrix of consideration weights, which is a by-product of every transformer layer and never cross on from one layer to a different. Every component within the matrix signifies the eye from one token to a different. The decrease the load, the much less consideration the question token offers to the important thing token.
Consideration weights should not symmetric, as question and key tokens serve completely different roles. The question token is the one being processed, and the important thing token is the one being referenced. Within the first heatmap, for instance, the phrase “of” could attend strongly to “the,” “united,” and “states”—however not essentially the opposite method round. Apparently, “the” may also attend strongly to “of,” indicating bidirectional consideration in sure circumstances.
Whereas it’s not at all times apparent why the mannequin attends the way in which it does, particularly since completely different heads could concentrate on completely different roles, an in depth inspection can reveal patterns. Some heads could give attention to syntax, others on semantics or named entities. If you happen to visualize a special layer or head, the heatmap could look fully completely different.
Within the second heatmap, consideration is averaged throughout all heads, offering a basic view of how phrases relate to at least one one other within the sentence. The stronger the eye between two phrases, the stronger their modeled relationship.
These visualizations supply insights into how the mannequin interprets and processes textual content.
Additional Studying
Beneath are some additional readings that you simply would possibly discover helpful:
Abstract
On this put up, you discovered how one can generate and visualize context vectors utilizing transformer fashions. Particularly, you explored:
- How context vectors seize contextual data
- The right way to extract context vectors utilizing a transformer mannequin
- The right way to use context vectors for contextual phrase disambiguation
- The right way to visualize consideration patterns in a transformer mannequin
Source link