


Let’s Construct a RAG-Powered Analysis Paper Assistant
Picture by Writer | Ideogram
Within the period of generative AI, folks have relied on LLM merchandise akin to ChatGPT to assist with duties. For instance, we will rapidly summarize our dialog or reply the arduous questions. Nevertheless, generally, the generated textual content isn’t correct and irrelevant.
The RAG approach is rising to assist resolve the issue above. Utilizing the exterior information supply, an LLM can achieve context not current in its information coaching. This methodology will improve mannequin accuracy and permit the mannequin to entry real-time information.
Because the approach improves output relevancy, we will construct a selected venture round them. That’s why this text will discover how we will construct a analysis paper assistant powered by RAG.
Preparation
For starters, we have to create a digital surroundings for our venture. You possibly can provoke it with the next code.
|
python venv –m your_virtual_environment_name |
Activate the digital surroundings, after which set up the next libraries.
|
pip set up streamlit PyPDF2 sentence–transformers chromadb litellm langchain langchain–group python–dotenv arxiv huggingface_hub |
Moreover, don’t overlook to amass a Gemini API key and a HuggingFace token to entry the repository, as we’ll use them.
Create the file known as app.py for constructing the assistant and .env file the place you set the API key.
With all the things in place, let’s begin to construct the assistant.
RAG-Powered Analysis Paper Assistant
Let’s begin constructing our venture. We are going to develop our analysis paper assistant with two totally different options for references. First, we will add our PDF analysis paper and retailer it in a vector database for customers to retrieve later. Second, we might search analysis papers inside the arXiv paper database and retailer them within the vector database.
The picture beneath exhibits this workflow for reference. The code for this venture can be saved within the following repository.
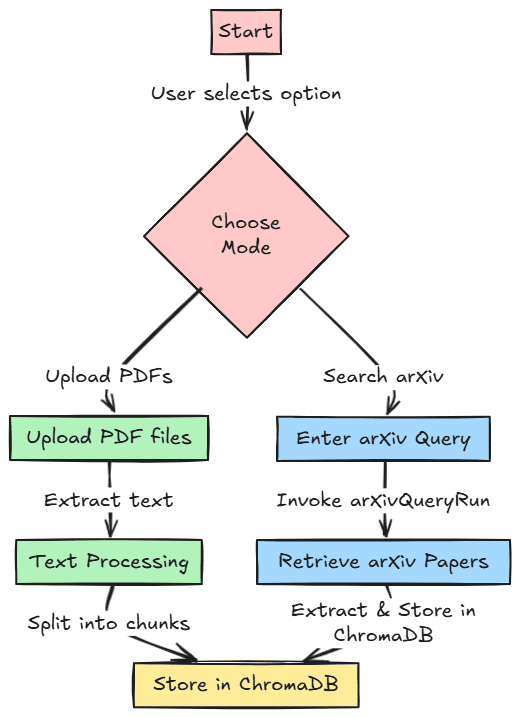
First, we should import all of the required libraries and provoke all of the surroundings variables we used for the venture.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import os import PyPDF2 import streamlit as st from sentence_transformers import SentenceTransformer import chromadb from litellm import completion from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.instruments import ArxivQueryRun from dotenv import load_dotenv
load_dotenv() gemini_api_key = os.getenv(“GEMINI_API_KEY”) huggingface_token = os.getenv(“HUGGINGFACE_TOKEN”)
if huggingface_token: login(token=huggingface_token)
consumer = chromadb.PersistentClient(path=“chroma_db”) text_embedding_model = SentenceTransformer(‘all-MiniLM-L6-v2’) arxiv_tool = ArxivQueryRun() |
After we import all of the libraries and provoke the variables, we’ll create helpful capabilities for our venture.
Utilizing the code beneath, we’ll create a perform to extract textual content information from PDF information.
|
def extract_text_from_pdfs(uploaded_files): all_text = “” for uploaded_file in uploaded_files: reader = PyPDF2.PdfReader(uploaded_file) for web page in reader.pages: all_text += web page.extract_text() or “” return all_text |
Then, we develop a perform to just accept the beforehand extracted textual content and retailer it within the vector database. The perform may also preprocess the uncooked textual content by splitting it into chunks.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def process_text_and_store(all_text): text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=50, separators=[“nn”, “n”, ” “, “”] ) chunks = text_splitter.split_text(all_text) strive: consumer.delete_collection(identify=“knowledge_base”) besides Exception: cross
assortment = consumer.create_collection(identify=“knowledge_base”)
for i, chunk in enumerate(chunks): embedding = text_embedding_model.encode(chunk) assortment.add( ids=[f“chunk_{i}”], embeddings=[embedding.tolist()], metadatas=[{“source”: “pdf”, “chunk_id”: i}], paperwork=[chunk] ) return assortment |
Lastly, we put together all of the capabilities for retrieval with semantic search utilizing embedding and generate the reply utilizing the retrieved paperwork.
|
def semantic_search(question, assortment, top_k=2): query_embedding = text_embedding_model.encode(question) outcomes = assortment.question( query_embeddings=[query_embedding.tolist()], n_results=high_ok ) return outcomes
def generate_response(question, context): immediate = f“Question: {question}nContext: {context}nAnswer:” response = completion( mannequin=“gemini/gemini-1.5-flash”, messages=[{“content”: prompt, “role”: “user”}], api_key=gemini_api_key ) return response[‘choices’][0][‘message’][‘content’] |
We at the moment are able to construct our RAG-powered analysis paper assistant. To develop the applying, we’ll use Streamlit to construct the front-end utility, the place we will select whether or not to add a PDF file or search arXiv instantly.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
def predominant(): st.title(“RAG-powered Analysis Paper Assistant”)
# Possibility to decide on between PDF add and arXiv search possibility = st.radio(“Select an possibility:”, (“Add PDFs”, “Search arXiv”))
if possibility == “Add PDFs”: uploaded_files = st.file_uploader(“Add PDF information”, accept_multiple_files=True, sort=[“pdf”]) if uploaded_files: st.write(“Processing uploaded information…”) all_text = extract_text_from_pdfs(uploaded_files) assortment = process_text_and_store(all_text) st.success(“PDF content material processed and saved efficiently!”)
question = st.text_input(“Enter your question:”) if st.button(“Execute Question”) and question: outcomes = semantic_search(question, assortment) context = “n”.be part of(outcomes[‘documents’][0]) response = generate_response(question, context) st.subheader(“Generated Response:”) st.write(response)
elif possibility == “Search arXiv”: question = st.text_input(“Enter your search question for arXiv:”)
if st.button(“Search ArXiv”) and question: arxiv_results = arxiv_tool.invoke(question) st.session_state[“arxiv_results”] = arxiv_results st.subheader(“Search Outcomes:”) st.write(arxiv_results)
assortment = process_text_and_store(arxiv_results) st.session_state[“collection”] = assortment
st.success(“arXiv paper content material processed and saved efficiently!”)
# Solely enable querying if search has been carried out if “arxiv_results” in st.session_state and “assortment” in st.session_state: question = st.text_input(“Ask a query in regards to the paper:”) if st.button(“Execute Question on Paper”) and question: outcomes = semantic_search(question, st.session_state[“collection”]) context = “n”.be part of(outcomes[‘documents’][0]) response = generate_response(question, context) st.subheader(“Generated Response:”) st.write(response) |
Within the code above, you’ll notice that our two options have been applied. To start out the applying, we’ll use the next code.

You will notice the above utility in your internet browser. To make use of the primary characteristic, you may strive importing a PDF analysis paper file, and the applying will course of it.

If it’s successful, an alert will signify that the information have been processed and saved inside the vector database.
Subsequent, attempt to enter any question to ask one thing associated to our analysis paper, and it’ll generate one thing like the next picture.

The result’s generated with the context we’re given, because it references any of our paperwork.
Let’s check out the arXiv paper search characteristic. For instance, right here is how we search the paper about MLOps and a pattern consequence.

If we a couple of paper now we have beforehand searched, we’ll see one thing just like the picture beneath.

And that, my buddies, is how we construct a RAG-powered analysis paper assistant. You possibly can tweak the code even additional to have extra particular options.
Conclusion
RAG is a generative AI approach that enhances the accuracy and relevance of responses by leveraging exterior information sources. RAG can be utilized to construct worthwhile functions, with one sensible instance being a RAG-powered analysis paper assistant.
In our journey now we have used Streamlit, LangChain, ChromaDB, the Gemini API, and HuggingFace fashions for embedding and textual content technology, which mixed effectively to construct our app, and we had been capable of add our PDF information or seek for papers instantly on arXiv.
I hope this has helped!
Source link