


The 2025 Machine Studying Toolbox: High Libraries and Instruments for Practitioners
Picture by Writer | Ideogram
2024 was the 12 months machine studying (ML) and synthetic intelligence (AI) went mainstream, affecting peoples’ lives in methods they by no means earlier than may have. With the introduction of huge language mannequin (LLM) merchandise in recent times corresponding to ChatGPT, corporations are racing to use the ability of ML, AI, and LLMs to their companies.
In 2025, many emerging trends throughout the ML world will proceed to be entrance and middle in lots of enterprise operations. Tendencies corresponding to brokers, generative AI, explainability, and extra will proceed to form our future. This implies we should always have the ability to sustain with these developments.
This text will discover the highest machine studying libraries and instruments for practitioners in 2025. The toolbox outlined on this article will turn out to be your baseline for navigating rising developments.
LangChain
The primary library you have to know in 2025 is LangChain, together with their prolonged household of merchandise.
Within the period of LLM functions, the power to shortly construct and deploy functions has turn out to be extra vital than ever. As a library, LangChain gives a framework to streamline the event of LLM-powered functions, making the method extra environment friendly and scalable.
LangChain gives many instruments that simplify the LLM utility improvement course of utilizing varied elements corresponding to chains, immediate templates, and extra. The framework additionally helps integration with varied LLM suppliers corresponding to OpenAI, Gemini, and Hugging Face.
Nevertheless, an excellent higher motive for adopting LangChain is its lively improvement and powerful open supply neighborhood. With this help, LangChain may be the proper device for constructing your LLM utility.
LangChain additionally stands out due to the instruments inside its household, particularly LangGraph and LangSmith. LangGraph is constructed on high of LangChain to handle agentic workflow utilizing a graph-based strategy. In the meantime, LangSmith enhances LangChain and LangGraph by offering instruments for the applying lifecycle, corresponding to monitoring, testing, and optimization.
Let’s check out the LangChain library. First, we are going to set up the library:
|
pip set up langchain langchain–google–gen |
We can even use the Gemini model because the LLM engine, so you’ll have to purchase an API key. Subsequent, we arrange the library and LLM for our utility:
|
from langchain_google_genai import ChatGoogleGenerativeAI from langchain.prompts import PromptTemplate from langchain_core.output_parsers import StrOutputParser
llm = ChatGoogleGenerativeAI( mannequin=“gemini-1.5-flash”, temperature=0.7, google_api_key=‘YOUR-API-KEY’ ) |
Lastly, we arrange the immediate template and the sequence to offer a response from the LLM.
|
immediate = PromptTemplate(input_variables=[“topic”], template=“Write a brief story about {subject}.”) runnable_sequence = immediate | llm | StrOutputParser() response = runnable_sequence.invoke({“subject”: “a courageous knight”}) print(response) |
We already arrange the LLM functions with only a few strains above. In fact, this implementation remains to be quite simple and desires extra consideration and extra tweaks to be steady in manufacturing, nevertheless it ought to show how highly effective LangChain may be with only a few strains of code.
JAX
In case you are an information scientist or have beforehand developed machine studying fashions with Python, it’s possible you’ll be aware of the NumPy library. JAX is a Python library that gives numerical computational like NymPy however with highly effective capabilities for machine studying analysis and implementation.
The Google staff develops JAX to permit high-performance computation and to offer options corresponding to computerized differentiation, vectorization, or just-in-time (JIT) compilation. The options are designed to attain intensive computation with ease. JAX has been utilized in many machine studying functions. The module gives many APIs appropriate for high-performance simulation and experiments.
Let’s try JAX with the next code. First, we set up.
Now we are able to check out the JAX computational features. For instance, we are going to compute the gradient from the given operate.
|
import jax.numpy as jnp from jax import grad, jit, vmap
def f(x): return jnp.sin(x) * jnp.cos(x)
df = grad(f) print(df(0.5)) |
And the output from the above code could be:
We will additionally vectorize the operate and apply it to the array.
|
f_vmap = vmap(f) print(f_vmap(jnp.array([0.1, 0.2, 0.3]))) |
And the output:
|
[0.09933467 0.19470917 0.28232124] |
You may test the documentation to study extra in regards to the library. It gives in depth materials that you would be able to discover to grasp the way it works.
Fastai
The subsequent device is Fastai, which gives a quick implementation of deep studying strategies and helper performance. The library is designed to simplify neural community coaching utilizing high-level elements that enable practitioners to attain nice outcomes with minimal code.
The Fastai library is constructed on high of the PyTorch library, a lot of the PyTorch energy and suppleness is obtainable from inside. Nevertheless, Fastai gives a a lot simpler method for customers to construct fashions because the library abstracts a variety of the advanced code right into a easy API. Nonetheless, Fastai can be utilized to create customized fashions because the library additionally gives low-level elements.
Fastai helps many duties, corresponding to laptop imaginative and prescient, tabular knowledge, pure language processing, and so on. Relying in your wants, you need to use the code as it’s or progressively enhance the complexity as required.
Let’s attempt to use the library to grasp it higher.
First, we have to set up the Fastai library. I like to recommend utilizing Miniconda, however you can too use different set up strategies. The PyTorch library can also be vital, as it’s a prerequisite.
You may set up the library through pip utilizing the next code:
As soon as you put in the Fastai library we are able to use it to construct a deep studying mannequin for ourselves. For instance, we are going to create a sentiment textual content classifier mannequin utilizing knowledge from Kaggle.
Let’s put together the textual content knowledge and all of the required libraries for the tutorial.
|
from fastai.textual content.all import * import pandas as pd from sklearn.model_selection import train_test_split
df = pd.read_csv(‘Corona_NLP_test.csv’) df.head()
df = df[[‘OriginalTweet’, ‘Sentiment’]] train_df, valid_df = train_test_split(df, test_size=0.2, random_state=42) |
Subsequent, we are going to carry out mannequin fine-tuning utilizing Fastai. Earlier than constructing the mannequin classifier, let’s have a look at how the library can help with fine-tuning duties.
We should put together the dataset in a format that Fastai may use utilizing the next code.
|
dls = TextDataLoaders.from_df(pd.concat([train_df, valid_df]), text_col=‘OriginalTweet’, label_col=‘Sentiment’, valid_pct=0.2, seed=42, text_vocab=None, is_lm=True) |
This tutorial will use and fine-tune the AWD-LSTM structure, as proven within the code under. You may tweak the educational price and the epoch quantity if you want as effectively.
|
study = language_model_learner(dls, AWD_LSTM, drop_mult=0.5, metrics=[accuracy, Perplexity()]) study.fine_tune(10, 2e–3) study.save_encoder(‘fine_tuned_encoder’) |
The code above will fine-tune the language mannequin object and consequence within the mannequin object being saved in your listing. You now have your base language mannequin. Let’s see find out how to fine-tune the pre-trained language mannequin for the textual content classifier.
We’ll put together the dataset as soon as extra however with a tweak this time.
|
dls_clas = TextDataLoaders.from_df( pd.concat([train_df, valid_df]), text_col=‘OriginalTweet’, label_col=‘Sentiment’, valid_pct=0.2, seed=42, text_vocab=dls.vocab, is_lm=False ) |
You may see that I set the text_vocab parameter utilizing vocabulary from the dataset used for fine-tuning to take care of consistency, and set the is_lm to False to make sure the mannequin is aware of it’s for use for classification duties.
Then, we practice the classifier with the next code.
|
learn_clas = text_classifier_learner(dls_clas, AWD_LSTM, drop_mult=0.5, metrics=accuracy) learn_clas = learn_clas.load_encoder(‘fine_tuned_encoder’) learn_clas.fine_tune(10, 2e–3) |
We’ve now completed growing our mannequin classifier and obtained the mannequin. We will see how the mannequin performs in opposition to the take a look at dataset utilizing the code under.
|
learn_clas.show_results() |
You may also take a look at the classifier mannequin with the next code.
|
test_text = “It is a good tweet” prediction = learn_clas.predict(test_text) prediction[0] |
Output:
That’s how simply you could possibly practice your mannequin with Fastai. You need to use the documentation to discover different use instances.
IntepretML
With explainability and ethics turning into more and more outstanding developments in 2025, we have to perceive why our machine studying fashions produce the outputs they do. Because of this IntepretML needs to be in your machine studying toolbox.
InterpretML is a Python library developed by Microsoft that permits customers to coach interpretable machine studying fashions, such because the explainable boosting machine (EBM), and to clarify black field fashions utilizing strategies like SHAP and LIME. Moreover, it provides an interactive visualization dashboard for in-depth exploration of mannequin explanations.
Let’s see the way it works utilizing the pocket book instance. First, we have to set up the IntepretML library.
Subsequent, we are going to put together the pattern dataset by preprocessing it and utilizing an EBM mannequin to coach the classifier.
|
import pandas as pd import seaborn as sns from sklearn.model_selection import train_test_split from interpret.glassbox import ExplainableBoostingClassifier from interpret import present
titanic = sns.load_dataset(‘titanic’) titanic = titanic[[‘pclass’, ‘age’, ‘sibsp’, ‘parch’, ‘fare’, ‘survived’]].dropna() X_train, X_test, y_train, y_test = train_test_split(titanic.drop(‘survived’, axis =1), titanic[‘survived’], test_size=0.20, random_state=42)
ebm = ExplainableBoostingClassifier() ebm.match(X_train, y_train) |
As soon as the mannequin is prepared, we are able to look at the library’s explainability. We’ll look at the worldwide explainability which is the mannequin’s general explainability.
|
ebm_global = ebm.explain_global() present(ebm_global) |
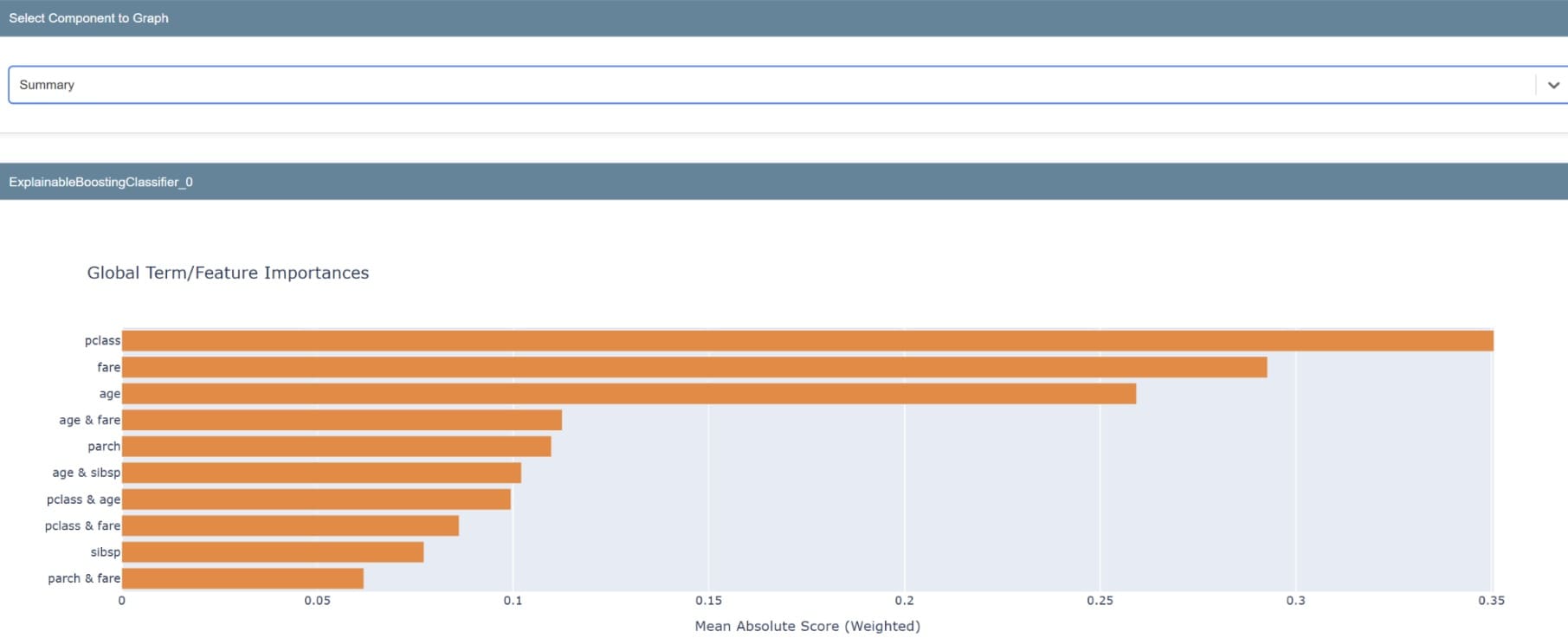
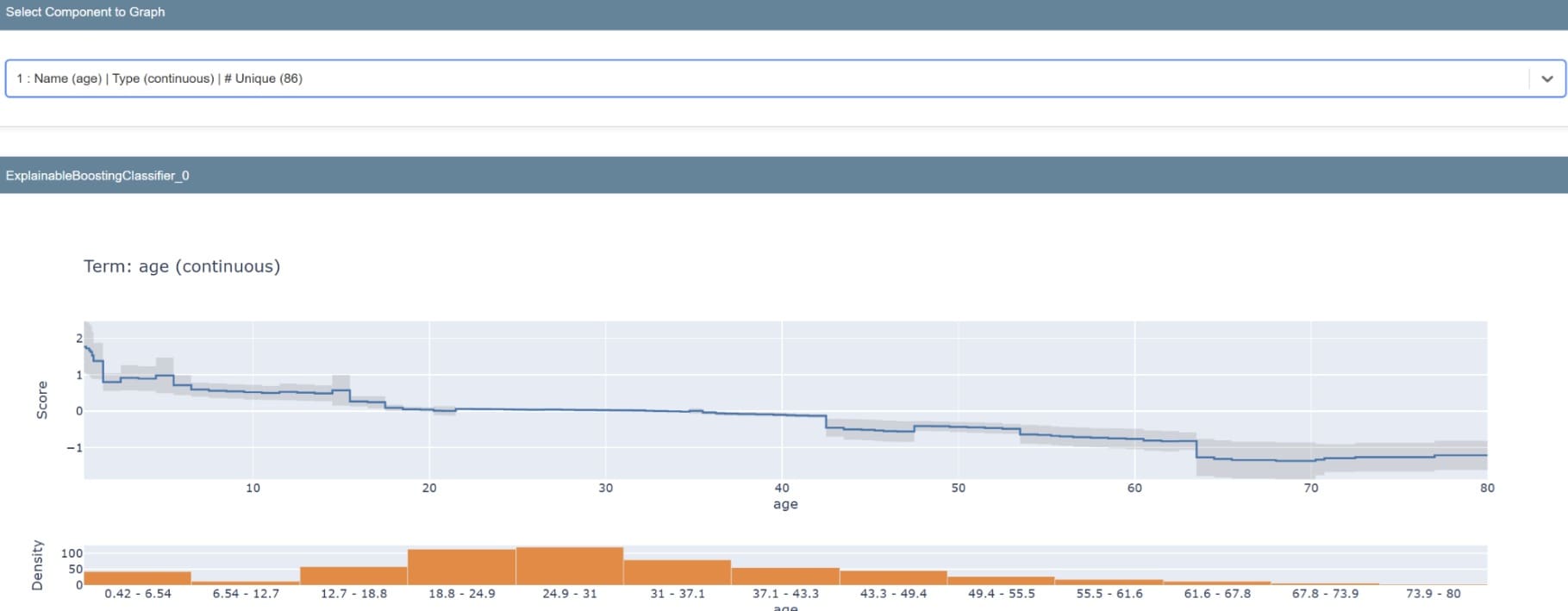
The abstract will produce a graph exhibiting the significance of our mannequin’s options. A single function may also be examined to grasp its prediction distribution.
If we wish to see how the mannequin predicts singular knowledge, the next code permits us to take action.
|
pattern = X_test.iloc[0:1] ebm_local = ebm.explain_local(pattern) present(ebm_local) |
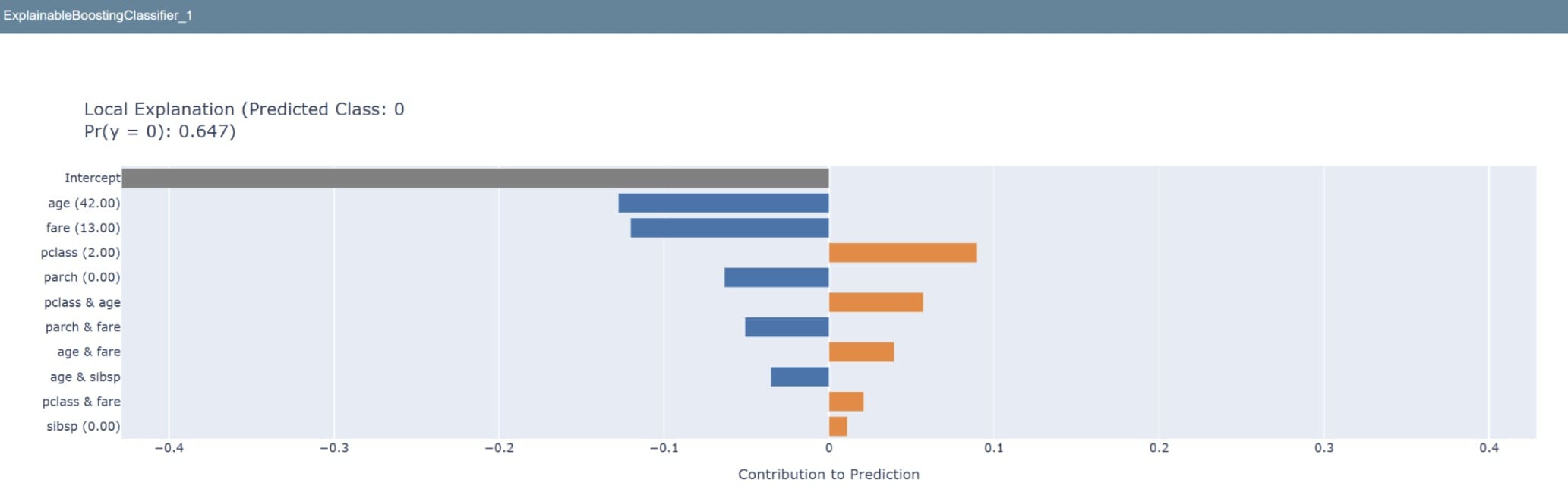
Attempt utilizing this library to assist acquire the belief of the stakeholders. Explainability is how non-technical folks will perceive what occurs inside your mannequin.
TokenSHAP
SHAP is a method that we use to have explainability from our mannequin for the worldwide and native ranges utilizing the Shapley worth. TokenSHAP makes use of the SHAP approach to interpret the LLM utilizing the Monte Carlo Shapley Worth Estimation approach. The library will estimate particular person tokens’ Shapley values and clarify how every token contributes to the mannequin determination.
Let’s check out the library by first putting in it.
Then, we are going to use TokenSHAP to grasp how the immediate contributes to the Gemini mannequin consequence. To do this, we are going to develop a customized class that TokenSHAP can course of.
|
from token_shap import * import google.generativeai as genai
genai.configure(api_key=‘YOUR-API-KEY’)
class GeminiModel(Mannequin): def __init__(self, model_name): self.mannequin = genai.GenerativeModel(model_name) def generate(self, immediate): response = self.mannequin.generate_content(immediate) return response.textual content |
When the mannequin is prepared, we are going to use it to carry out a SHAP evaluation on the LLMs.
|
gemini_model = GeminiModel(“gemini-1.5-flash”)
splitter = StringSplitter() token_shap = TokenSHAP(gemini_model, splitter, debug=False)
immediate = “Why is the solar sizzling?”
df = token_shap.analyze(immediate, sampling_ratio=0.3, print_highlight_text=True) token_shap.plot_colored_text() |
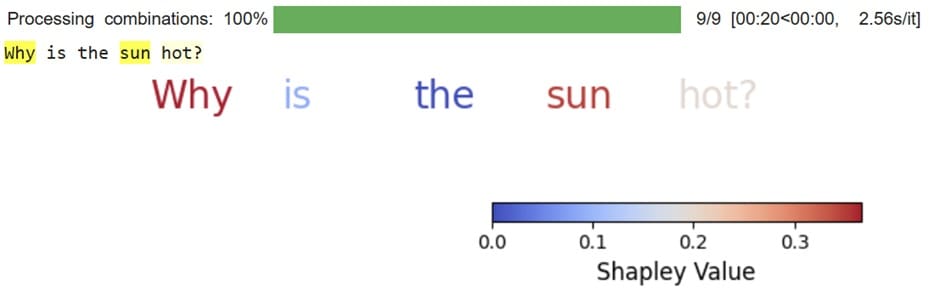
The result’s a person token coloured based mostly on its Shapley Worth. The upper the Shapley worth, the extra influential that token is to the mannequin response. For instance, the phrases why and solar are far more vital than the phrase the when offering output.
Utilizing the code under, you can too get the precise Shapley worth for every token.
|
token_shap.shapley_values |
Output:
|
{‘Why_1’: 0.3667134604734776, ‘is_2’: 0.08749906167069088, ‘the_3’: 0.0, ‘sun_4’: 0.35029929597949777, ‘sizzling?_5’: 0.1954881818763337} |
Attempt using TokenSHAP to grasp why your LLM gives sure output and which tokens performs the better roles within the course of.
Conclusion
This text explored a collection of highly effective instruments shaping machine studying in 2025 — from the speedy utility improvement enabled by the LangChain household to the high-performance numerical capabilities of JAX. We additionally appeared into Fastai’s streamlined deep studying framework, the interpretability benefits supplied by InterpretML, and the token-level insights offered by TokenSHAP. Every of those libraries not solely exemplifies rising developments like generative AI and enhanced mannequin explainability but additionally equips you with sensible, hands-on approaches for tackling advanced challenges in in the present day’s data-driven panorama.
Shifting ahead, harnessing these instruments will empower you to construct strong, scalable, and clear ML options. Embrace these improvements to refine your workflows and drive impactful outcomes, assured that you’re well-prepared to guide within the evolving world of machine studying and synthetic intelligence.
I hope this has helped!
Source link