


The Newbie’s Information to Clustering with Python
Picture by Writer | Ideogram
Clustering is a extensively utilized technique in lots of domains like buyer and picture segmentation, picture recognition, bioinformatics, and anomaly detection, all to group knowledge into clusters by way of similarity. Clustering strategies have a double-sided nature: as a machine studying method aimed toward discovering data beneath unlabeled knowledge (unsupervised studying), and as a descriptive knowledge evaluation instrument for uncovering hidden patterns in knowledge.
This text offers a sensible hands-on introduction to frequent clustering strategies that can be utilized in Python, particularly k-means clustering and hierarchical clustering.
Primary Ideas & Sensible Concerns
Implementing a clustering technique entails a number of concerns or inquiries to ask.
Dimension and Dimensionality of the Dataset
The dimensions of your dataset and the variety of options it incorporates affect not solely clustering efficiency and high quality but additionally the computational effectivity of the method of discovering clusters. For very high-dimensional knowledge, think about using dimensionality discount strategies like PCA, which may enhance clustering accuracy and scale back noise. Giant datasets could demand superior optimized strategies based mostly on the fundamental ones we’ll show on this article however with some added complexities.
Variety of Clusters to Discover
It is a essential however oftentimes not trivial query to ask. You might have a big buyer base with hundreds of consumers and will wish to phase them into teams of consumers with comparable procuring conduct? Chances are high you don’t have a clue of the variety of segments you wish to discover a priori. Nicely-established strategies like strategies just like the elbow technique, silhouette evaluation, or perhaps a human knowledgeable’s area data may help make this important resolution. Too few clusters could not result in significant distinctions, whereas too many could trigger mannequin overfitting or lack of generalization to future knowledge.
Guiding Criterion for Clustering
Choosing an ample similarity metric can be key to discovering significant clusters. The Euclidean distance performs properly on compact and spherical-looking clusters, however different metrics like cosine similarity or Manhattan distance may very well be a wiser alternative for extra irregular constructions. The selection of the clustering algorithm (e.g., k-means, hierarchical clustering, DBSCAN, and so forth) have to be aligned with the information’s distribution and the issue’s wants.
Time to see two sensible examples of clustering in Python.
Sensible Instance 1: k-means Clustering
This primary instance exhibits a simple utility of k-means to phase a dataset of consumers in a shopping center based mostly on two options: annual revenue and spending retailer. You’ll be able to have a full take a look at the dataset and its options here.
As normal, every little thing in Python begins by importing the required packages and the information:
|
import pandas as pd import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.preprocessing import StandardScaler
url = “https://uncooked.githubusercontent.com/gakudo-ai/open-datasets/refs/heads/major/Mall_Customers.csv” df = pd.read_csv(url) |
We now choose the specified options, positioned within the fourth and fifth columns. Moreover, standardizing the information normally helps discover higher-quality clusters, particularly when the ranges of values throughout options range.
|
X = df.iloc[:, [3, 4]].values scaler = StandardScaler() X_scaled = scaler.fit_transform(X) |
We now use the imported KMeans to make use of Scikit-learn library’s implementation of k-means. Importantly, k-means is an iterative clustering technique that requires specifying the variety of clusters a priori. Let’s suppose a advertising and retail knowledgeable instructed us a priori that it would make sense to attempt to discover 5 subgroups within the knowledge. We then apply k-means as follows.
|
# Okay-means with ok=5 clusters kmeans = KMeans(n_clusters=5, random_state=42, n_init=10) df[‘Cluster’] = kmeans.fit_predict(X_scaled) |
Discover how we added a brand new function, referred to as ‘Cluster’ to the dataset, containing the identifier of the cluster the place each buyer has been assigned. This might be very useful shortly, to plotting the clusters utilizing completely different colours and visualizing the consequence.
|
# Plot clusters plt.scatter(X[:, 0], X[:, 1], c=df[‘Cluster’], cmap=‘viridis’, edgecolors=‘ok’) plt.xlabel(‘Annual Earnings’) plt.ylabel(‘Spending Rating’) plt.title(‘Okay-Means Clustering’) plt.present() |

Appears like our knowledgeable’s instinct was fairly proper! In case you might be uncertain, you possibly can strive utilizing the elbow technique with completely different settings of the variety of clusters to search out probably the most promising setting. This article explains how to do that on the identical dataset and situation.
Sensible Instance 2: Hierarchical Clustering
In contrast to k-means, hierarchical clustering strategies don’t strictly necessitate specifying a priori the variety of clusters however as an alternative, create a hierarchical construction referred to as a dendrogram that allows versatile cluster choice. Let’s see how.
|
import scipy.cluster.hierarchy as sch from sklearn.cluster import AgglomerativeClustering |
Earlier than making use of agglomerative clustering, we plot a dendrogram of our beforehand processed and scaled dataset: this may occasionally assist us decide an optimum variety of clusters (let’s simply faux for a second we forgot what our knowledgeable instructed us earlier).
|
plt.determine(figsize=(8, 5)) dendrogram = sch.dendrogram(sch.linkage(X_scaled, technique=‘ward’)) plt.title(‘Dendrogram’) plt.xlabel(‘Clients’) plt.ylabel(‘Euclidean Distance’) plt.present() |
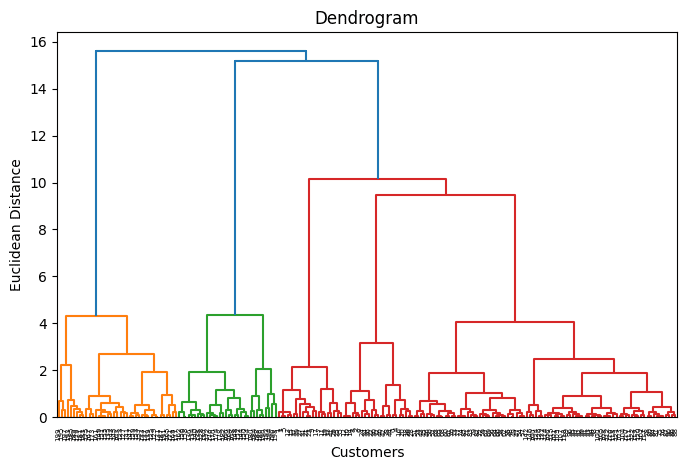
As soon as once more, ok=5 appears like an excellent variety of clusters. The reason being that in case you drew a horizontal line reducing via the dendrogram in some unspecified time in the future the place vertical branches being lower are neither too distanced nor too concentrated, you’d accomplish that on the peak the place the dendrogram is lower 5 occasions horizontally.
Right here’s how we apply the hierarchical clustering algorithm and visualize the outcomes.
|
hc = AgglomerativeClustering(n_clusters=5, affinity=‘euclidean’, linkage=‘ward’) df[‘Cluster_HC’] = hc.fit_predict(X_scaled)
plt.scatter(X[:, 0], X[:, 1], c=df[‘Cluster_HC’], cmap=‘plasma’, edgecolors=‘ok’) plt.xlabel(‘Annual Earnings’) plt.ylabel(‘Spending Rating’) plt.title(‘Hierarchical Clustering’) plt.present() |
Moreover the variety of clusters sought, we additionally specified the affinity or similarity measure, particularly Euclidean distance, in addition to the linkage coverage, which determines how distances between clusters are calculated: in our case, we selected ward linkage, which minimizes the variance inside merged clusters for extra compact grouping.
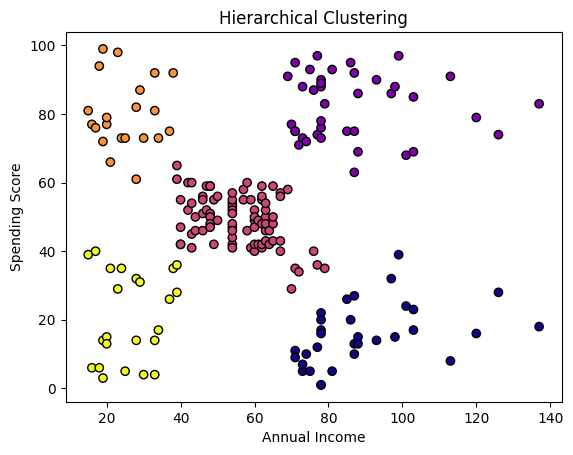
These outcomes look similar to these achieved with k-means, with just a few delicate variations primarily in factors on the boundaries between clusters.
Nicely carried out!
Source link