


Understanding RAG Half IV: RAGAs & Different Analysis Frameworks
Picture by Editor | Midjourney & Canva
Remember to try the earlier articles on this sequence:
Retrieval augmented era (RAG) has performed a pivotal function in increasing the bounds and overcoming many limitations of standalone massive language fashions (LLMs). By incorporating a retriever, RAG enhances response relevance and factual accuracy: all it takes is leveraging exterior data sources like vector doc bases in real-time, and including related contextual data to the unique consumer question or immediate earlier than passing it to the LLM for the output era course of.
A pure query arises for these diving into the realm of RAG: how can we consider these far-from-simple programs?
There exist a number of frameworks to this finish, like DeepEval, which gives over 14 analysis metrics to evaluate standards like hallucination and faithfulness; MLflow LLM Consider, identified for its modularity and ease, enabling evaluations inside customized pipelines; and RAGAs, which focuses on defining RAG pipelines, offering metrics resembling faithfulness and contextual relevancy to compute a complete RAGAs high quality rating.
Right here’s a abstract of those three frameworks:
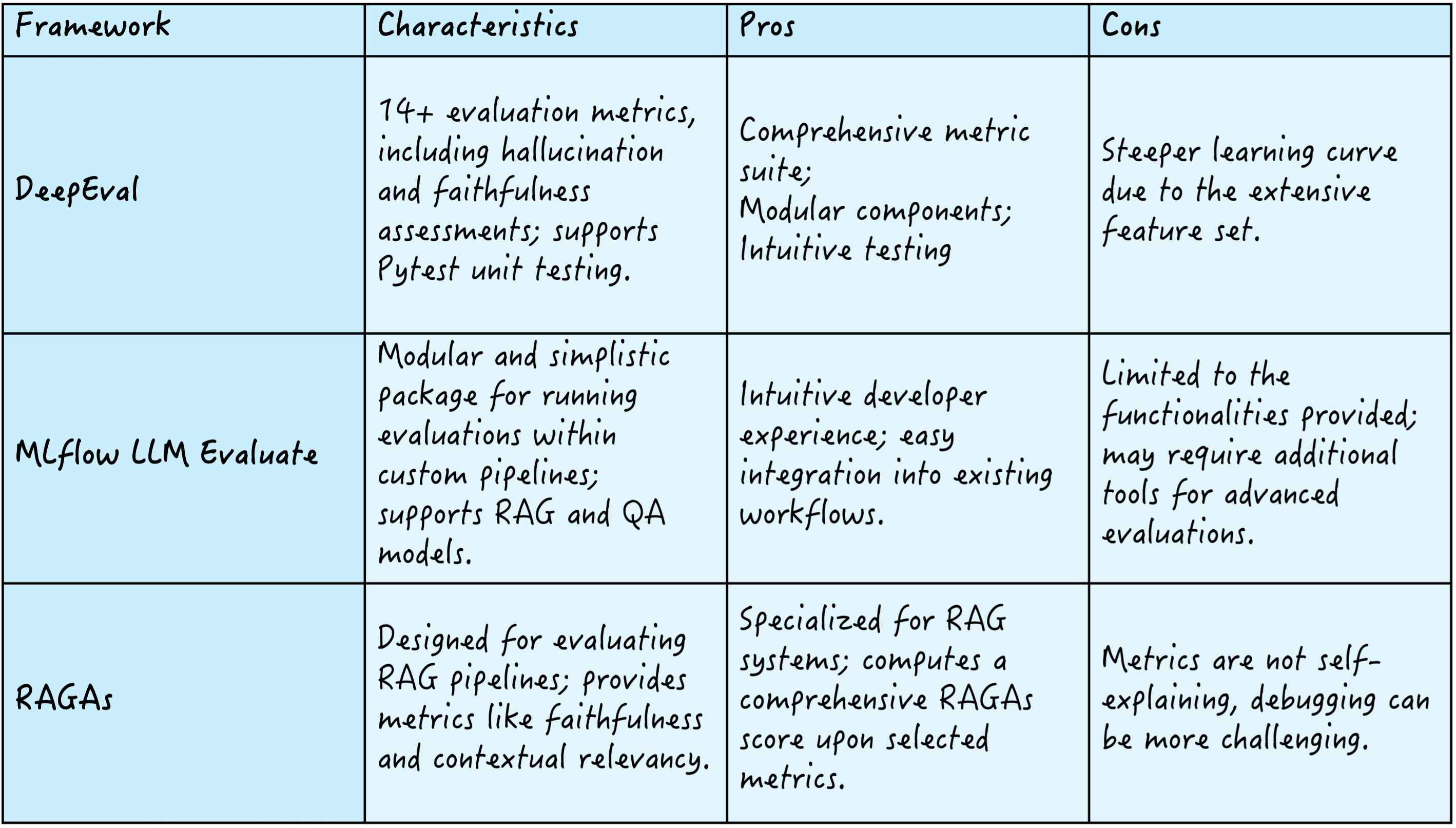
RAG analysis frameworks
Let’s additional study the latter: RAGAs.
Understanding RAGAs
RAGAs (an abbreviation for retrieval augmented era evaluation) is taken into account the most effective toolkits for evaluating LLM purposes. It succeeds in evaluating the efficiency of a RAG system’s components &madsh; particularly the retriever and the generator in its easiest strategy — each in isolation and collectively as a single pipeline.
A core component of RAGAs is its metric-driven growth (MDD) strategy, which depends on knowledge to make well-informed system selections. MDD entails repeatedly monitoring important metrics over time, offering clear insights into an software’s efficiency. Moreover permitting builders to evaluate their LLM/RAG purposes and undertake metric-assisted experiments, the MDD strategy aligns nicely with software reproducibility.
RAGAs parts
- Prompt object: A part that defines the construction and content material of the prompts employed to elicit responses generated by the language mannequin. By abiding with constant and clear prompts, it facilitates correct evaluations.
- Evaluation Sample: A person knowledge occasion that encapsulates a consumer question, the generated response, and the reference response or floor fact (much like LLM metrics like ROUGE, BLEU, and METEOR). It serves as the fundamental unit to evaluate an RAG system’s efficiency.
- Evaluation dataset: A set of analysis samples used to guage the general RAG system’s efficiency extra systematically, primarily based on varied metrics. It goals to comprehensively appraise the system’s effectiveness and reliability.
RAGAs Metrics
RAGAs gives the aptitude of configuring your RAG system metrics, by defining the precise metrics for the retriever and the generator, and mixing them into an general RAGAs rating, as depicted on this visible instance:
Let’s navigate a number of the most typical metrics within the retrieval and era sides of issues.
Retrieval efficiency metrics:
- Contextual recall: The recall measures the fraction of related paperwork retrieved from the data base throughout the ground-truth top-k outcomes, i.e., how lots of the most related paperwork to reply the immediate have been retrieved? It’s calculated by dividing the variety of related retrieved paperwork by the whole variety of related paperwork.
- Contextual precision: Inside the retrieved paperwork, what number of are related to the immediate, as a substitute of being noise? That is the query answered by contextual precision, which is computed by dividing the variety of related retrieved paperwork by the whole variety of retrieved paperwork.
Era efficiency metrics:
- Faithfulness: It evaluates whether or not the generated response aligns with the retrieved proof, in different phrases, the response’s factual accuracy. That is often executed by evaluating the response and retrieved paperwork.
- Contextual Relevancy: This metric determines how related the generated response is to the question. It’s sometimes computed both primarily based on human judgment or through automated semantic similarity scoring (e.g., cosine similarity).
For instance metric that bridges each points of a RAG system — retrieval and era — now we have:
- Context utilization: This evaluates how successfully an RAG system makes use of the retrieved context to generate its response. Even when the retriever fetched glorious context (excessive precision and recall), poor generator efficiency could fail to make use of it successfully, context utilization was proposed to seize this nuance.
Within the RAGAs framework, particular person metrics are mixed to calculate an general RAGAs rating that comprehensively quantifies the RAG system’s efficiency. The method to calculate this rating entails deciding on related metrics and calculating them, normalizing them to maneuver in the identical vary (usually 0-1), and computing a weighted common of the metrics. Weights are assigned relying on every use case’s priorities, for example, you would possibly need to prioritize faithfulness over recall for programs requiring sturdy factual accuracy.
Extra about RAGAs metrics and their calculation via Python examples will be discovered here.
Wrapping Up
This text introduces and gives a normal understanding of RAGAs: a preferred analysis framework to systematically measure a number of points of RAG programs efficiency, each from an data retrieval and textual content era standpoint. Understanding the important thing components of this framework is step one in direction of mastering its sensible use to leverage high-performing RAG purposes.
About Iván Palomares Carrascosa
Iván Palomares Carrascosa is a frontrunner, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the actual world.
Source link