


Understanding RAG Half IX: Positive-Tuning LLMs for RAG
Picture by Editor | Midjourney & Canvas
You’ll want to try the earlier articles on this collection:
In earlier articles of the Understanding RAG collection, which focuses on numerous elements of retrieval augmented technology, we put the lens on the retriever part that’s built-in with a big language mannequin (LLM) to retrieve significant and truthful context information to boost the standard of LLM inputs and, consequently, its generated output response. Concretely, we realized how you can handle the size of the context handed to the LLM, how you can optimize retrieval, and the way vector databases and indexing methods work to retrieve information successfully.
This time, we’ll shift our consideration to the generator part, that’s, the LLM, by investigating how (and when) to fine-tune an LLM inside an RAG system to make sure its responses preserve being coherent, factually correct, and aligned with domain-specific information.
Earlier than shifting on to understanding the nuances of fine-tuning an LLM that’s a part of an RAG system, let’s recap the notion and technique of fine-tuning in “standard” or standalone LLMs.
What’s LLM Positive-Tuning?
Identical to a newly bought cellphone is tuned with personalised settings, apps, and an ornamental case to swimsuit the preferences and character of its proprietor, fine-tuning an current (and beforehand educated) LLM consists of adjusting its mannequin parameters utilizing extra, specialised coaching knowledge to boost its efficiency in a particular use case or utility area.
Positive-tuning is a crucial a part of LLM growth, upkeep, and reuse, for 2 causes:
- It permits the mannequin to adapt to a extra domain-specific, usually smaller, dataset, bettering its accuracy and relevance in specialised areas comparable to authorized, medical, or technical fields. See the instance within the picture under.
- It ensures the LLM stays up-to-date on evolving information and language patterns, avoiding points like outdated info, hallucinations, or misalignment with present details and greatest practices.
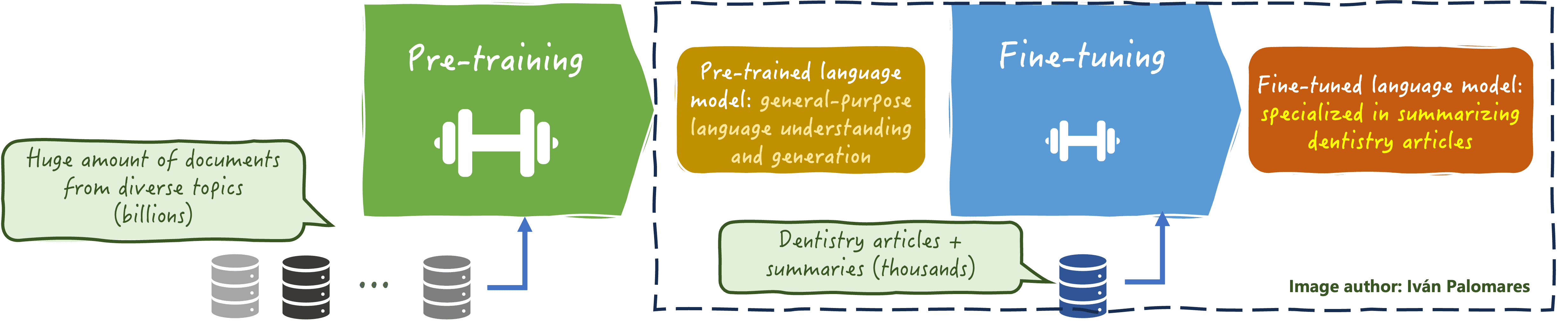
LLM fine-tuning
The draw back of preserving an LLM up to date by periodically fine-tuning all or a few of its parameters is, as you may guess, the price, each when it comes to buying new coaching knowledge and the computational assets required. RAG helps cut back the necessity for fixed LLM fine-tuning. Nonetheless, fine-tuning the underlying LLM to an RAG system stays helpful in sure circumstances.
LLM Positive-Tuning in RAG Methods: Why and How?
Whereas in some utility eventualities, the retriever’s job of extracting related, up-to-date info for constructing an correct context is sufficient to not want periodical LLM retraining, there are extra concrete circumstances the place this isn’t enough.
One instance is when your RAG utility requires a really deep and bold understanding of specialised jargon or domain-specific reasoning not captured by means of the LLM’s authentic coaching knowledge. This could possibly be a RAG system within the medical area, the place it might do an awesome job in retrieving related paperwork, however the LLM could battle in appropriately decoding items of information within the enter earlier than being fine-tuned on particular datasets that include helpful info to assimilate such domain-specific reasoning and language interpretation mechanisms.
A balanced fine-tuning frequency in your RAG system’s LLM may additionally assist enhance system effectivity, as an illustration by lowering extreme token consumption and consequently avoiding pointless retrieval.
How does LLM fine-tuning happen from the angle of RAG? Whereas a lot of the classical LLM fine-tuning may also utilized to the RAG system, some approaches are notably fashionable and efficient in these programs.
Area-Adaptive Pre-training (DAP)
Regardless of its title, DAP can be utilized as an intermediate technique between normal mannequin pretraining and task-specific fine-tuning of base LLMs inside RAG. It consists in using a domain-specific corpus to have the mannequin acquire a greater understanding of a sure area, together with jargon, writing types, and so forth. Not like standard fine-tuning, it might nonetheless use a comparatively massive dataset, and it usually is finished earlier than integrating the LLM with the remainder of the RAG system, after which extra targeted and task-specific fine-tuning on smaller datasets would happen as a substitute.
Retrieval Augmented Positive-Tuning
That is an and extra RAG-specific fine-tuning technique, whereby the LLM is particularly retrained on examples that incorporate each the retrieved context — augmented LLM enter — and the specified response. This makes the LLM extra expert at leveraging and optimally using retrieved information, producing responses that may higher combine that information. In different phrases, by means of this technique, the LLM will get extra expert in correctly utilizing the RAG structure it sits on.
Hybrid RAG Positive-Tuning
Additionally known as hybrid instruction-retrieval fine-tuning, this strategy combines conventional instruction fine-tuning (coaching an LLM to comply with directions by exposing it to examples of instruction-output pairs) with retrieval strategies. Within the dataset used for this hybrid technique, two kinds of examples coexist: some embrace retrieved info whereas others include instruction-following info. The consequence? A extra versatile mannequin that may make higher use of retrieved info and in addition comply with directions correctly.
Wrapping Up
This text mentioned the LLM fine-tuning course of within the context of RAG programs. After revisiting fine-tuning processes in standalone LLMs and outlining why it’s wanted, we shifted the dialogue to the need of LLM fine-tuning within the context of RAG, describing some fashionable methods usually utilized to fine-tune the generator mannequin in RAG functions. Hopefully that is info you should utilize shifting ahead with your individual RAG system implementation.
Source link