


Understanding RAG Half VII: Vector Databases and Indexing Methods
Picture by Editor | Midjourney & Canva
You should definitely try the earlier articles on this sequence:
Effectively retrieving information in RAG programs is essential to offering correct and well timed responses. Vector databases and indexing methods play an important position in strengthening RAG programs’ efficiency. This text continues the Understanding RAG sequence by conceptualizing vector databases and indexing methods generally utilized in RAG programs. It goals to demystify their position, clarify how they work, and clarify why they’re important to most RAG programs.
What are Vector Databases?
Merely put, a vector database is a specialised sort of database optimized for the storage and retrieval of textual content represented as high-dimensional vectors.
Why are these databases essential for RAG? As a result of vector representations allow environment friendly similarity-based searches over giant doc bases, shortly retrieving related data based mostly on a person question. In a vector database, semantically comparable paperwork have nearer vector representations.
As an illustration, the vectors related to two Mediterranean restaurant opinions can be far more comparable to one another than these related to a Spanish restaurant assessment and a information article about classical music. Equally, paperwork containing textual content that’s semantically related to the person question shall be retrieved effectively via vector operations like dot merchandise and cosine similarity.
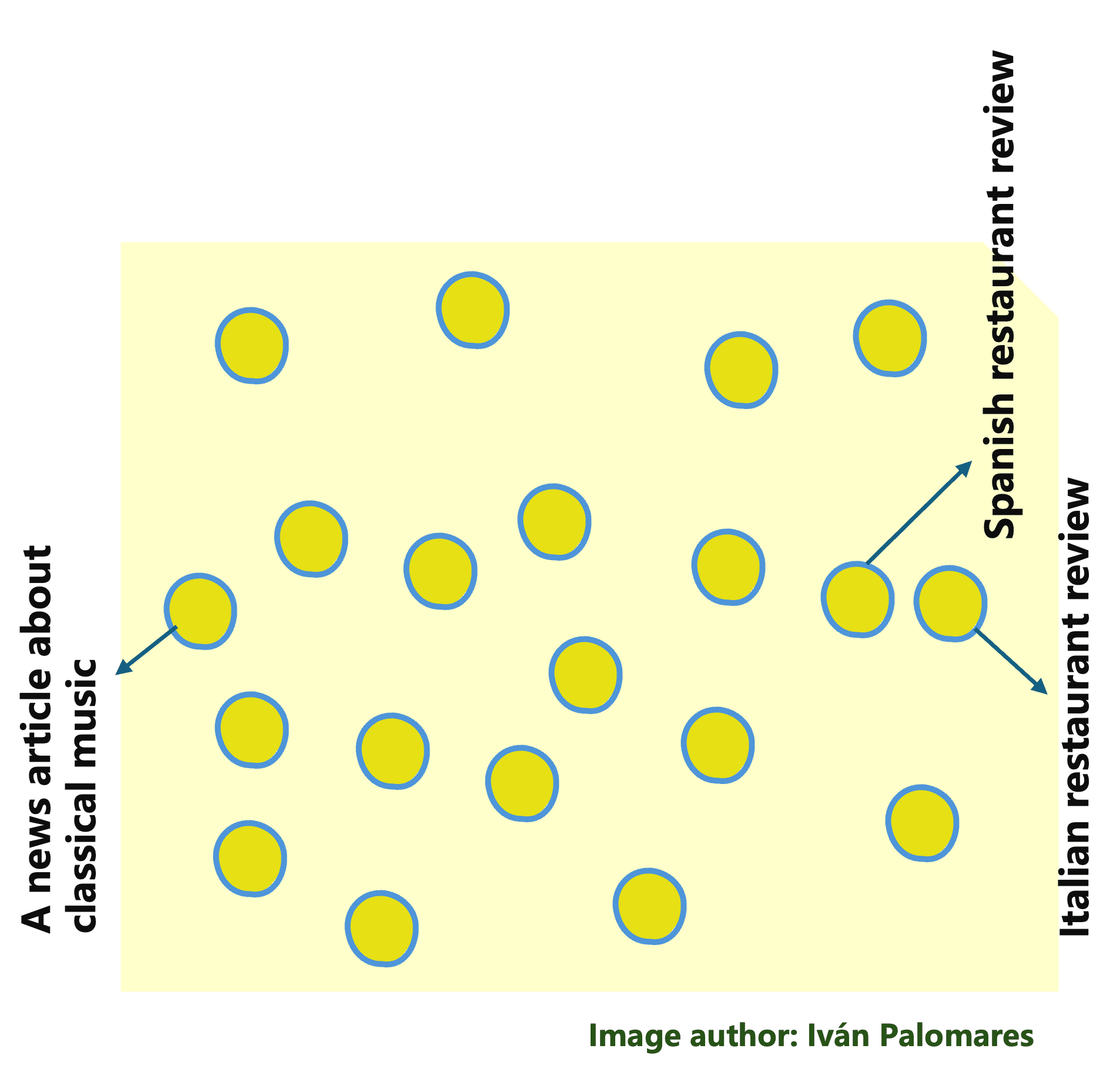
In a vector database, vector representations of semantically comparable paperwork are shut to one another.
You will need to perceive the distinction between vector databases and conventional databases. Whereas conventional databases depend on structured knowledge and actual matching, vector databases help unstructured retrieval, permitting for semantic searches relatively than keyword-based lookups.
Overview and Affect of Indexing Methods in RAG
The following query to reply is: how do RAG programs effectively retrieve data from vector databases? The reply lies in indexing methods, designed to hurry up similarity searches whereas sustaining accuracy. Utilizing an indexing technique is like discovering a ebook in a library by referencing a catalog as a substitute of manually scanning each shelf.
The next are frequent indexing methods applied in RAG programs:
- Approximate Nearest Neighbors (ANN): A quick method that considerably reduces search time, although it sacrifices some accuracy in favor of effectivity
- Hierarchical Navigable Small World (HNSW): A well-liked technique that balances velocity and accuracy by organizing knowledge in a multi-layer graph construction for optimized nearest neighbor searches
- IVF (Inverted File Index): This technique enhances large-scale search effectivity by splitting high-dimensional vectors into clusters, thereby turning the retrieval course of quicker when dealing with huge datasets
- PQ (Product Quantization): Utilized in superior RAG programs, this technique compresses vector knowledge to scale back reminiscence utilization whereas enabling environment friendly similarity searches
A well-implemented indexing technique mixed with a strong vector database can affect the efficiency of RAG programs in a number of methods.
First, the accuracy and velocity trade-off in retrieval will get optimized, guaranteeing that searches stay each environment friendly and related.
Second, indexing performs a central position in lowering latency with out compromising the high quality of responses generated by the RAG system. This in flip facilitates quicker and extra scalable information retrieval.
Third, completely different RAG purposes might profit from distinct indexing methods. As an illustration, real-time conversational AI assistants might prioritize HNSW indexing for fast but correct retrieval, whereas large-scale doc search engines like google would possibly lean in the direction of IVF indexing to effectively handle huge datasets.
Widespread Misconceptions
One frequent false impression is the assumption that having extra vectors in your database implies higher retrieval. That is basically false as a result of retrieval high quality will depend on the relevance of vectors within the database and the effectiveness of the indexing technique, relatively than on the amount of knowledge saved. Actually, extra vectors can yield elevated noise, making it tougher to retrieve actually related outcomes effectively.
In the meantime, concerning indexing methods, whereas a brute drive just like the actual nearest neighbor technique — i.e. discovering the most comparable vector to the enter question — would possibly sound too sluggish to be helpful, there are circumstances when it’s preferable, for instance when working with small datasets the place actual nearest neighbor search gives most accuracy with out vital efficiency loss.
It is usually necessary to make clear that approximate searches don’t inherently trigger inaccuracies, however relatively they will help considerably enhance retrieval effectivity whereas holding high-quality outcomes via well-designed efficiency-precision trade-offs.
Wrapping Up
Understanding vector databases and indexing methods is essential for designing environment friendly and efficient RAG programs. These two parts immediately affect retrieval velocity, accuracy, and RAG system efficiency. We outlined a number of indexing methods and mentioned some misconceptions about vector retrieval and sure search and indexing approaches.
The following submit of this sequence will study methods to mitigate hallucinations in RAG programs: these are among the largest challenges in producing dependable responses in RAG programs and language fashions as an entire.
Source link