


Understanding RAG Half X: RAG Pipelines in Manufacturing
Picture by Editor | Midjourney & Canvas
You’ll want to take a look at the earlier articles on this sequence:
Pipelines play a central function in deploying software program, as they facilitate the automation and orchestration of a number of duties in manufacturing environments, guaranteeing easy knowledge and course of flows. Within the context of superior programs, like retrieval augmented technology (RAG) functions, pipelines in manufacturing attain much more significance. They’re essential in sustaining affordable ranges of effectivity, scalability, consistency amongst elements, and reliability whereas managing advanced workflows.
This a part of the Understanding RAG sequence focuses on discussing the important thing traits of RAG pipelines in manufacturing, distinguishing between three varieties of pipelines: the indexing pipeline, the retrieval pipeline, and the technology pipeline. Every kind of pipeline has its function within the general RAG structure, and understanding how they work together is important for optimizing efficiency and having the system produce well timed, related, and factually right outcomes.
Alongside the beneath description of the three RAG pipelines, we will likely be exploring the weather proven on this visible diagram:
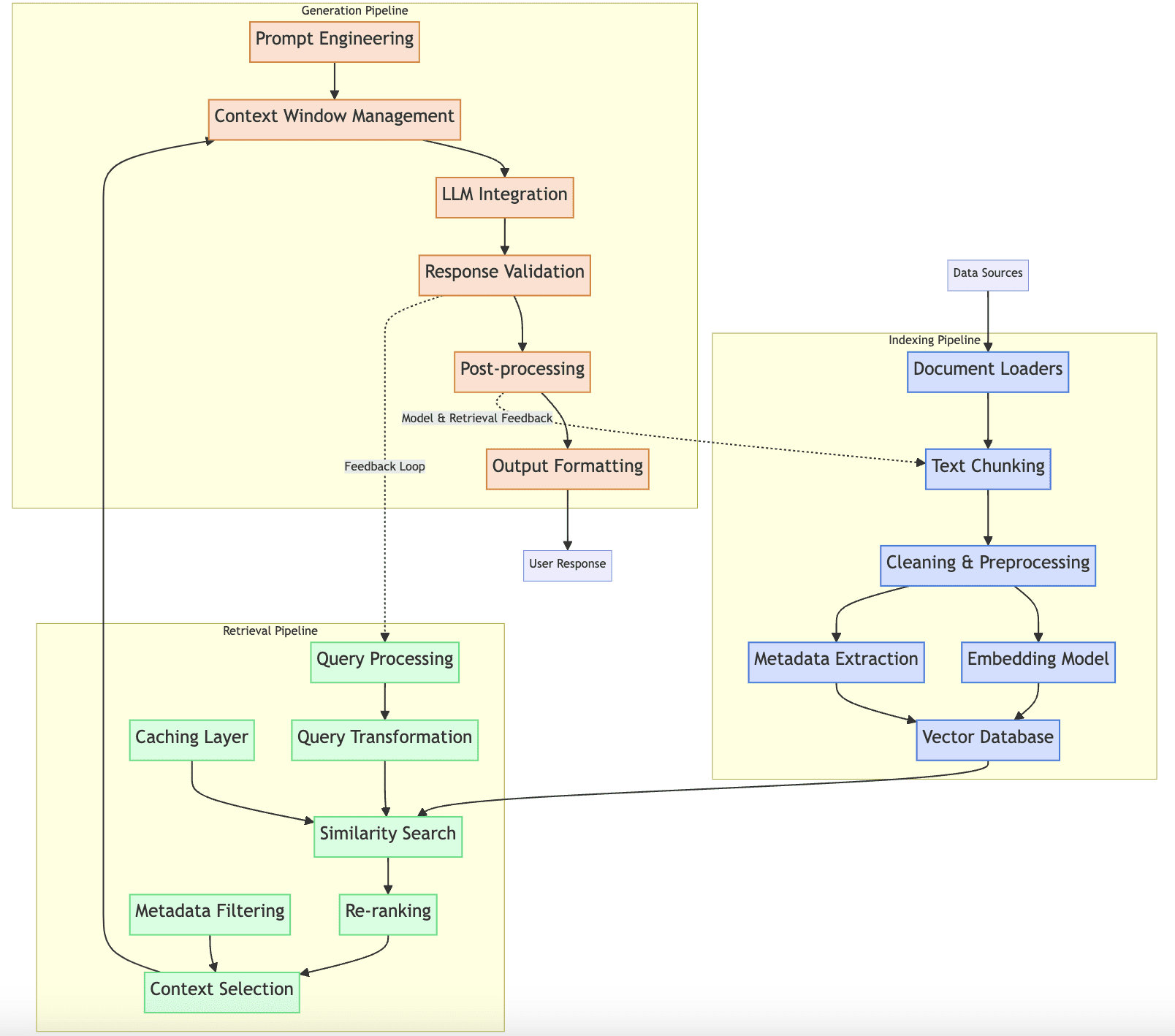
RAG manufacturing pipelines
Indexing Pipeline
The aim of the indexing pipeline in an RAG system is to gather, course of, and retailer paperwork in a vector database for environment friendly retrieval. Merely put, the indexing pipeline takes care of the RAG system’s doc database.
To do that, it depends on the next elements:
- Doc loaders that acquire and cargo paperwork for a number of sources in several codecs like PDF, net pages, and so forth.
- Textual content chunking methods to make sure lengthy paperwork are built-in into the vector database in manageable parts. These methods embrace overlap settings to maintain the semantic relationship between chunks from the identical doc.
- Knowledge pre-processing workflows, that apply steps like cleansing, filtering, and eradicating duplicates in document-related knowledge.
- Embedding fashions that can convert the textual content to numerical vector representations or embeddings.
- The vector database the place paperwork will likely be saved for future retrieval
- Strategies for doc metadata extraction.
These elements are orderly represented contained in the “indexing pipeline” block within the diagram proven earlier. How does an indexing pipeline work together with the opposite pipelines within the RAG system? As you could guess, this pipeline supplies processed and saved paperwork to the retrieval pipeline, after having utilized some similarity-based seek for occasion. The processes going down alongside the pipeline should be designed in an aligned and coherent trend with the retrieval technique: for example, the chunking technique and settings usually affect retrieval high quality. A great upkeep technique for the indexing pipeline should help incremental updates to have contemporary knowledge accessible anytime.
Retrieval Pipeline
The retrieval pipeline is liable for discovering and extracting probably the most related context from the vector database each time a question is submitted by a consumer. It straight communicates with the opposite two RAG pipelines — indexing pipeline and technology pipeline — and its elements are:
- Question understanding and preprocessing: earlier than processing the question, an easier language mannequin centered on language understanding duties like intent recognition or named entity recognition (NER) might be used for a greater understanding of the unique question earlier than preprocessing it.
- Question transformation mechanisms like question growth, decomposition, and so forth.
- The similarity search algorithm is a key a part of the RAG system’s retriever and this pipeline. By interacting with the vector database by means of orchestration with the indexing pipeline, similarity metrics like cosine or Euclidean distance are used to search out probably the most related saved paperwork to the processed question. A caching layer can be utilized right here to effectively handle frequent queries.
- If we implement a re-ranking technique, the re-ranking mechanism turns into additionally a part of this pipeline.
- Context filtering or choice primarily based on metadata, to pick out probably the most related data among the many retrieved paperwork.
This pipeline may be additional enhanced by incorporating hybrid search capabilities, like semantic and keyword-based search.
By way of interactions, the retrieval pipeline consumes knowledge from the indexing pipeline and sends the retrieved context it builds to the technology pipeline that governs the RAG system’s language mannequin. It may additionally present suggestions to the indexing pipeline for optimizing its operation.
Technology Pipeline
This pipeline has the purpose of making coherent, correct responses using the language mannequin and the retrieved context constructed by the retrieval pipeline. Its key elements or levels are:
- Immediate engineering and templating to organize the context because the language mannequin’s enter.
- Context window administration is critical in circumstances like dealing with lengthy context to make sure related data suits inside the language mannequin’s limitations like enter token size.
- LLM choice and configuration are essential in real-world RAG functions that often have a number of fashions fine-tuned for specialised duties like summarization, translation, or sentiment evaluation.
- Response validation procedures to validate and post-process the uncooked generated output.
- Response formatting and structuring for its presentation to the tip consumer.
The technology pipeline receives the related context from the retrieval pipeline and serves as the ultimate part that delivers responses to customers. It may embrace suggestions loops primarily based on interplay with the opposite elements for fostering steady enchancment.
Wrapping Up
This text of the RAG sequence mentioned the three most important varieties of pipelines an RAG system usually integrates as soon as deployed in manufacturing environments. For optimum RAG utility efficiency and assured success, it will be important that every pipeline is monitored, versioned, and enhanced independently whereas making certain they function collectively seamlessly.
About Iván Palomares Carrascosa
Iván Palomares Carrascosa is a frontrunner, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the true world.
Source link